
Один из способов структурирования хоккейных данных. Применение у него может быть самое разнообразное, например: определить стили игры команд в сравнении друг с другом, по нескольким критериям, создавать кластеры игроков похожих, или не похожих, по игре друг на друга по каким-либо показателям, что вполне применимо в скаутинге или подборе игрока под определённые требования.
С течением времени хоккейная статистика практически не оставляет "белых пятен" на площадке, добавляя всё новые и новые показатели, позволяя получать достаточно полные представления о происходящем во время игры. Группировать и осмысливать большие объёмы данных становится очень сложно, поэтому и применяются методы позволяющие автоматизировать этот процесс. На самом деле, мне самому не ясны многие производные анализа, на данный момент лишь открываю для себя различные свойства и области применения - зачастую достаточно неожиданные.
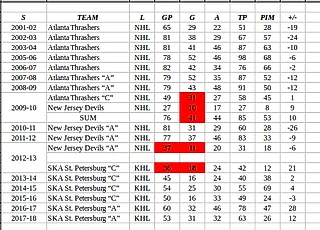
Для примера решил поупражняться на выборке российских игроков в НХЛ по результатам сезона 2017-2018. Теперь о исследуемой таблице данных. Выборка из 16 игроков с количеством игр в сезоне не менее =< 74GP. Представлены как форварды, так и защитники, сейчас грани между задачами игроков различных "амплуа" стираются, и мне самому интересно - каким образом сгруппируются данные. В графе "Имени и Фамилии" для наглядности добавил "Позицию" на площадке.
Создаём матрицу из данных и выводим их в виде дендограммы.
Обычно начинают с определения количества кластеров, но в данном случае пойдём "от обратного", это связано со структурой игры. "На полюсах" атаки и защиты оказались Овечкин и Задоров, соответственно. Сразу же разобьём дендограмму на 2 кластера вручную для наглядности и попробуем интерпретировать результат.
Получилось две большие группы. Начнём с "кластера обороны": Анисимов и Наместников - центральные нападающие оборонительного плана. Для российских защитников характерна роль домоседа и здесь, конечно, выделяется Проворов, который выполняет типичные оборонительные функции и вполне успешно атакующие.
В "кластере атаки" меня заинтересовала "похожесть" Дадонова и Радулова, видел мало их игр в НХЛ, запишу себе на полях - при случае обратить внимание.. Близки по стилю игры Тарасенко и Овечкин, Кучеров и Малкин, здесь каждый волен судить насколько это соответствует действительности.
В дальнейшем интерпретация полученных результатов ложится на плечи читателей, буду приводить только необходимую информацию. Для более точной интерпретации необходимы "реальные кластеры", то есть разбить матрицу на группы согласно какого-либо алгоритма. Начнём с простого метода известного под различными названиями: “метод каменистой осыпи”, "метод согнутого колена”, я использую "метод локтевого изгиба", как наиболее полно и понятно отражающего суть.
Достаточно резкий "изгиб локтя" заметен при k = 2, как раз деление кластеров на атаку и оборону, далее кривая функции достаточно плавная, что не даёт достаточной уверенности в выборе.
Модификация алгоритма k-средних - PAM, для определения количества кластеров.
2 кластера. Сказываются проблемы из-за размерности хоккейной статистики.
Критерий Калинского сам по себе достаточно своеобразный, в этот раз совсем не смог разбить данные на кластеры.
Делать нечего, сделаю вывод о количестве кластеров эмпирически, что затруднит оценку кластеризации, но подходит для хоккейной статистики.
Для подобных данных хорошо подходит кластеризация распространения аффинности.
Особняком Задоров, в одном кластере Овечкин и Тарасенко, в последнем кластере защитники Емелин, Орлов, Проворов, Сергачев, в большом(зелёном) кластере все остальные. На втором изображении показаны кластеры для критериев выборки.
Напоследок таблица с методом k-средних для четырёх кластеров. В столбце kmeans принадлежность игрока к номеру кластера.
Исчерпывающая информация. Подобным образом возможно группировать любые данные для поиска однородной статистики, и последующего анализа полученных групп.
Комментарии