
Технологии машинного обучения и искусственного интеллекта проникают в нашу жизнь. Наверное большинство из Вас хотя бы раз задавали какой-то вопрос ChatGPT, а может генерировали картинку в Midjourney. Прорыв больших языковых моделей (LLM, Large Language Model) в массы случился, когда в OpenAI решили прикрутить к своей модели веб-интерфейс для работы с ней, который стал доступен обычным людям. Приложение быстрее всех в истории собрало 100 миллионов пользователей, а слово ChatGPT вошло в лексикон.
Проникают техноголии AI и в футбол. Например есть модель TwelveGPT, которая дообучена на футбольных данных и может создавать отчёты об играх, как на картинке ниже.

Спортс.ру не Хабр, но всё-таки давайте договоримся о терминах. AI (ИИ) – искуственный интеллект, сейчас используется повсеместно. И, как обычно, разные люди вкладывают в него разные смыслы. Кто-то действительно верит, что компьютерный разум уже среди нас, кто-то раньше клепал на товары фразу «Без ГМО», а теперь «AI-powered», кто-то, как один из отцов-основателей глубокого обучения Ян ЛеКун, считает, что никакого искуственного интеллекта нет, а есть простое перемножение матриц. В данной статье термин AI будет использоваться в определении «Использование большой языковой модели».
Несколько месяцев назад на сайте одной экстремистской организации выложили кейс использования их LLM модели с открытым исходным кодом Llama 3.1-70B-Instruct в скаутской системе ФК Севилья, ScoutAdvisor. Модель позволяет обрабатывать с высокой скоростью большое количество скаутских отчётов, саммаризировать их и обогащать цифровые данные по игрокам мнением скаутов, что помогает сделать всесторонюю оценку игроков.
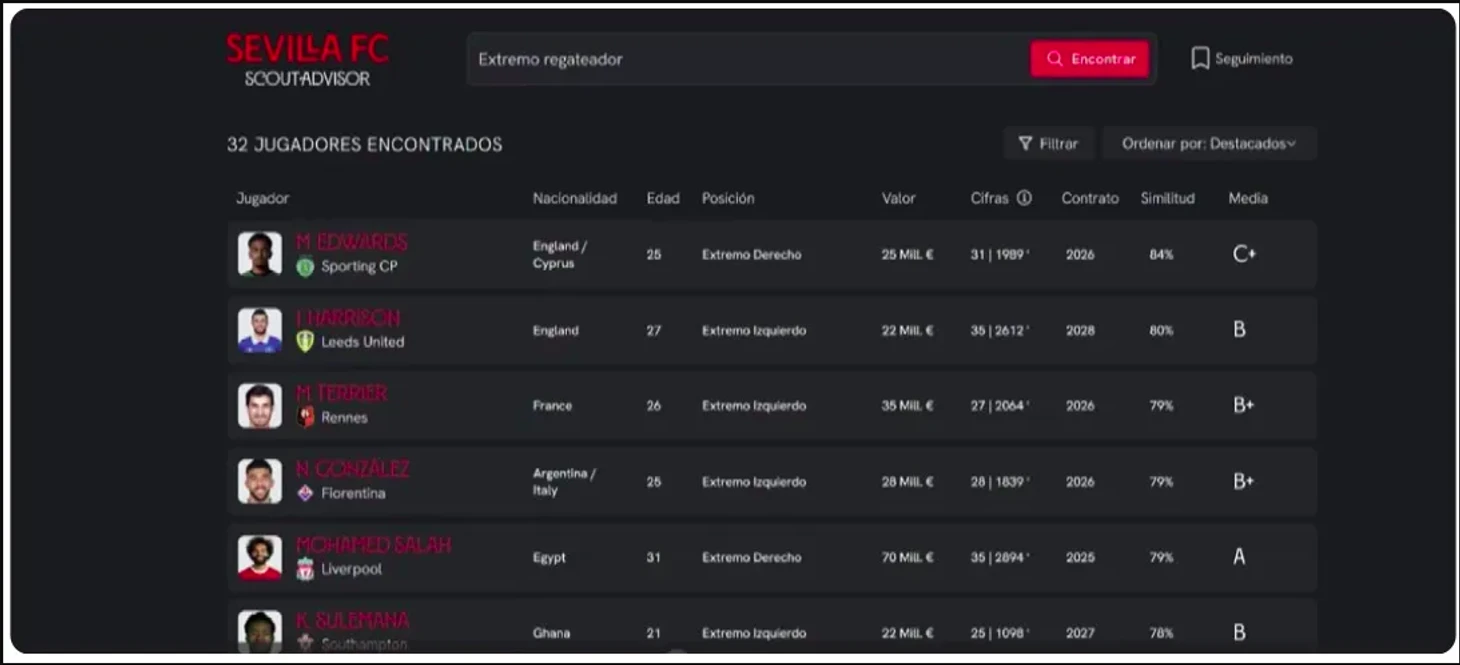
Зачем вообще могло понабодиться использовать LLM для поиска и оценки футболистов? Современные инструменты анализа данных об игроках позволяют хорошо и качественно работать со структурированными данными, например с таблицами в которых каждый столбец это определённая метрика игрока. Нет проблем взять набор признаков и на них обучить модель (от простой линейной регрессии до бустингов) которая будет предсказывать нужный Вам таргет. Однако такие модели имеют существенный минус – они либо вообще, либо очень плохо работают с неструктурированными данными, в первую очередь с текстом. С помощью них нельзя проанализировать скаутские отчёты и эта часть оценки игрока (оценка экспертом) в таких моделях не учитывается. При этом скаут мог заметить что-то, что незаметно в массиве цифр, но может быть важным при принятии решения по конкретному игроку. Здесь может прийти на помощь LLM, которую и тренировали на то, чтобы анализировать тексты, извлекать из них суть и давать по ним ответы (на самом деле её тренировали просто предсказывать следующий токен, а «понимание» текста это сторонний эффект, но не суть). В таком случае мы можем добавить в нашу систему экспертное мнение скаутов и при этом мы можем общаться с такой системой на естественном языке и очен быстро.
По словам Elias Zamora, Chief Data Officer at Sevilla FC (на русский можно перевести как Директор по данным) раньше скаутские отчёты в базе данных Севильи хранились в неструктурированном виде и для анализа одного списка игроков требовалось от 200-300 человекочасов на их поиск, чтение и обработку. Это типичный бизнес-кейс для внедрения LLM: есть база знаний компании в которой этих знаний много (Замора говорит о 300 тысячах отчётов), но получить их довольно сложно и долго.
Давайте рассмотрим как такая система работает и из каких компонентов она состоит. Начнём с блок-схемы:
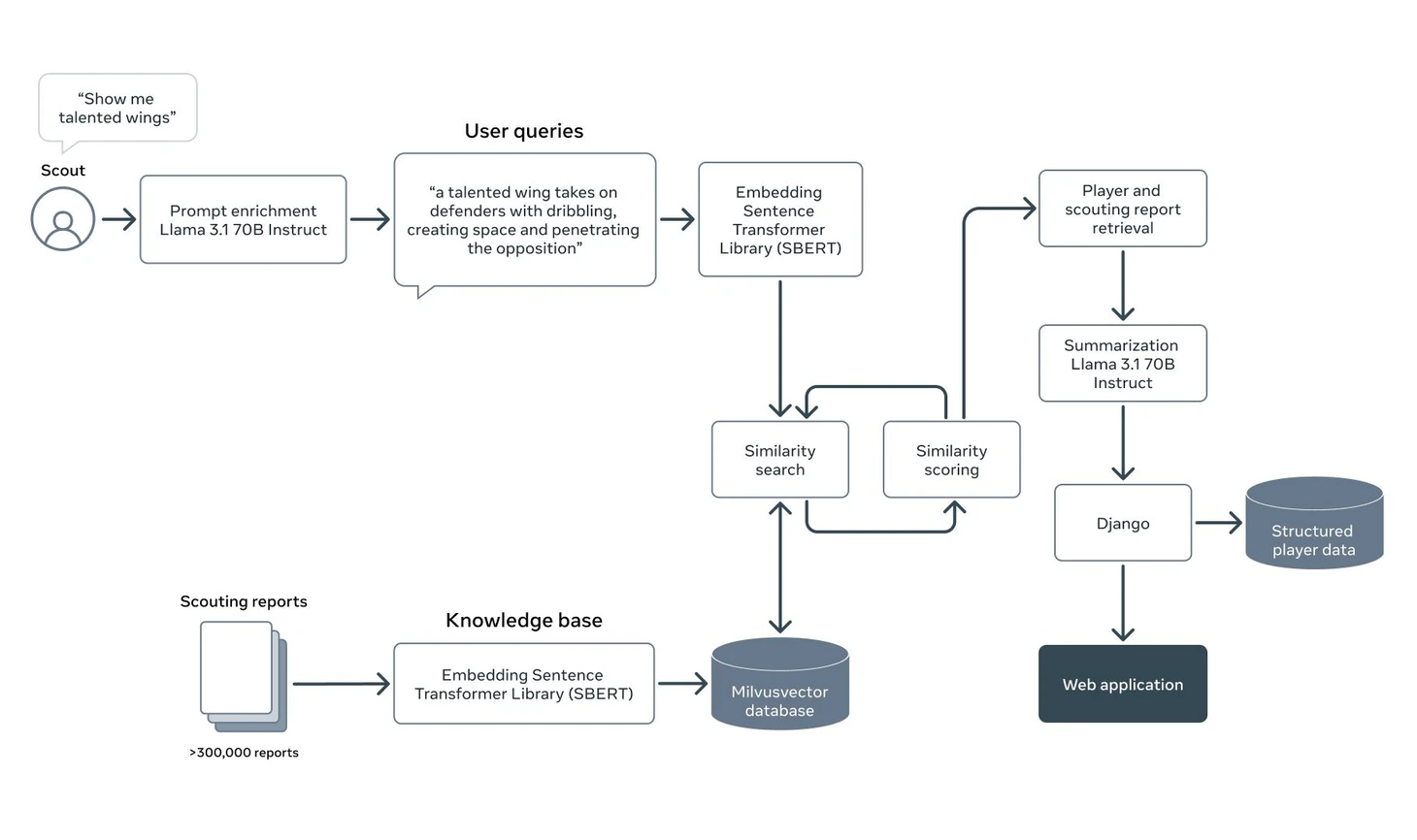
На вход она принимает вопрос от скаута на естественном языке, как если бы он разговаривал со своим коллегой. В примере он просит найти талантливых вингеров. Далее рассмотрим по шагам, что происходит с этим запросом.
Обогащение вопроса (prompt enrichment): на этой стадии вопрос от человека различными способами дополняется, чтобы модель обработала его как можно лучше. Здесь используются такие техники как перефразирование, добавление контекста, синонимов ключевых слов и т.п. Зачем всё это? Чтобы минимизировать случаи, когда релевантная информация не попадает в контекст из-за низкой оценки. Почему такое может случиться? В примере скаут просит найти ему вингеров. А допустим другой скаут, который составляет некоторую часть отчётов, не использует это слово, а называет их «левый/правый полузащитник». В таком случае есть вероятность, что retrieval-часть системы (та, которая ищет подходящий контент) может не воспринять эти отчёты как релевантные и не добавить их в контекст.
Само обогащение вопроса, обычно, делается с помощью запроса к LLM в котором говорится о необходимости вопрос обогатить, даются практические рекомендации как это сделать, может быть добавлется пара примеров.Векторизация текстовых данных (SBERT): на этом шаге мы с помощью специальной Embedding-модели, которая обучена конвертировать текст в числовой вектор с «сохранением» смысла, превращаем текст в вектор чисел. Пример из далёкого 2013 года, когда такие модели только появились: если из вектора слова «Король» вычесть вектор слова «Мужчина» получится вектор, который по значениям будет близок к вектору слова «Королева».
Тоже самое нужнос делать и со скаутскими отчётами. По классике документы разделяются на кусочки, которые называются чанками, и с помощью той же Embedding-модели превращаются в вектора, чтобы дальше мы могли проводить над ними математические операции, а именно рассчитать их (векторов) меру схожести. Вектора отчётов мы складываем в специальную базу данных, которая разработана для быстрой работы с векторами и назвается, сюрприз, векторной базой данных. Севилья (точнее IBM) использует, наверное, саму известную из них, Milvus. Если всё хорошо работает, то близкими будут вектора, которые закодированы из похожих по смыслу текстов.Векторный поиск (Similarity search and scoring): здесь мы считаем меру схожести между нашим вопросом и частями отчётов, которые лежат в векторной базе и оставлем N-нное количество документов, которые наиболее близки к нашему нему. Это и будет контекст, который мы передадим модели.
А зачем мы вообще ищем какие-то документы и считаем их релевантность, почему нельзя напрямую спросить у модели про вингеров? Потому что в данных, на которых модель обучалась, не было ни одного скаутского отчёта из системы Севильи и у модели нет этого знания. Поэтому мы помещаем в промпт контекст из нашей базы знаний и говорим: «Вот, изучи наши конфидециальные данные, а потом ответь на мой вопрос». А т.к. есть ограничения на длину контекста, нам приходится выбирать из него только нужные части.
На самом деле такой «ванильный» RAG редко когда работает хорошо и внутри наверняка есть дополнительные штуки (полнотекстовый поиск помимо векторного, реранкер), но в статье эти подробности опущены.Создание финального промпта (player and scouting report retrieval): получив контекст и улучшив наш вопрос мы можем создать финальную версию промпта, которая уже пойдёт в модель. Выглядять он будет примерно таким образом:
«Системный промпт»
————————————-
Вопрос
————————————-
Контекст из базы знаний»
В системном промпте мы можем задать поведение модели. Например: «Ты скаут клуба Севилья. Тебе нужно из полученной информации из скаутских отчётов составить саммари на талантливых игроков». Контекст – это те части нашей Базы знаний, которые retrieval-часть системы посчитала релевантными вопросу.Саммаризация данных отчётов с помощью LLM (Summarization Llama 3.1-70B-Instruct): ну а дальше начинается магия! Получив всю эту информацию LLM начинает токен за токеном генерировать ответ, который при правильной работе всей системы, можно назвать хорошим (или ответом, который дал бы скаут). Ответ также приходит в виде текста, возможно с ссылками на источники (конкретные отчёты об игроках в базе знаний), что делает работу с такой системой удобной.
Веб-приложение (Django, Web application): всё «общение» с LLM происходит в приложении ScoutAdvisor. Как именно в статье не сказано, но подозреваю, что реализован самый популярный вариант: чат с моделью. Или может мнение скаутов добавляется в выгрузку показателей игрока отдельным столбцом.
Вот так, вкратце, функционирует эта система. Благодаря её внедрению, поиск и анализ скаутских отчётов теперь занимает не часы (или недели в случае большого объёма исследуемых игроков), а секунды. С помощью этой системы Севилья планирует не только улучшать работу своего селекционного отдела, но и зарабатывать, продавая консалтинг-услуги. Безусловно, такая система не идеальна, поэтому она не замена людям, а помощник, который может очень-очень быстро выполнить рутинную работу.
Для внедрения AI, по словам Заморы, в клубе важно иметь три элемента:
Надёжную и качественную базу данных, откуда будет браться информация.
Глубокое понимание бизнеса (как, когда, почему и для чего эта система будет использоваться).
Квалифицированную команду, которая способна реализовывать AI-решения.
В конце хочу заметить, что данный кейс (RAG-система над базой знаний компании) – это не рокет-сайнс, а довольно рутинная вещь для многих компаний. Я сам реализовывал нечто подобное на своём проекте. Но радостно, что футбольные клубы здесь стараются идти в ногу со временем и внедрять технологии не спустя 10 лет после начала их использования, а вместе с другими бизнесами. Возможно, не за горами рассказ о внедрении LLM-агентов, например тех же LLM-скаутов, цель которых уже пробовать выполнить работу без вмешательства человека. Прекрасное это будущее или нет решайте сами, но оно точно интересное.
Если Вам понравился пост, подпишитесь на блог и на мой телеграм-канал Цифры в спорте, где я пишу о применении Data Science в спорте.













Комментарии