
Исследование блогера Sports.ru.
В предыдущей статье я рассказал о своей реализации модели из OptaPro. После того, как я с ней закончил, захотелось пойти дальше, а именно – попасть на ближайший форум от компании StatsBomb. Далее будет обзор и результаты моего первого исследования.
Я использовал открытые данные от StatsBomb, но, в отличие от предыдущего раза, обучалась модель на «Месси данных» – набор старых матчей Барселоны с начала карьеры Месси, а тестировалась на данных по чемпионату мира.

Основная идея
Суть исследования в том, чтобы попытаться объективно оценить качество атаки команды и влияние на это конкретных игроков. Для простоты представим каждую атаку (владение) последовательностью передач и разделим атаки на два типа – хорошие и плохие. Следующее утверждение может показаться спорным и является, по сути, допущением с целью упростить модель и сделать датасет более сбалансированным. Допустим, что плохие атаки – это те, которые заканчиваются потерей мяча, а хорошие – ударом по воротам. Таким образом, задача сводится к тому, чтобы для последовательностей векторов, представляющих пасы построить бинарный классификатор. Во второй части нужно математически оценить вклад каждого вектора в предсказание классификатора.
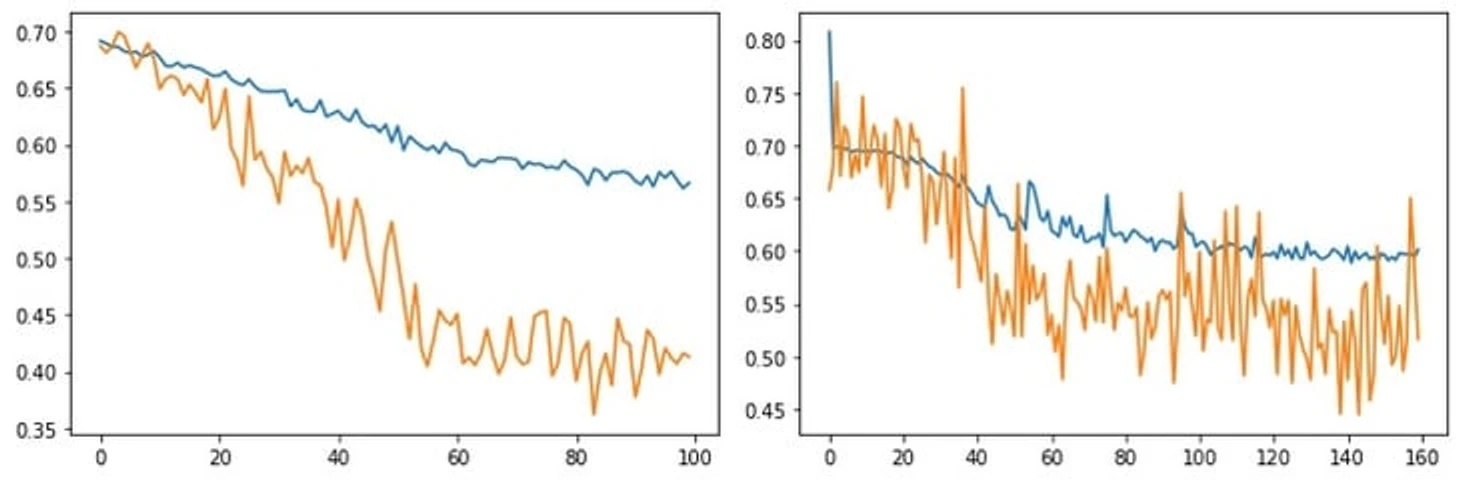
Забегая вперед, скажу, что из-за небольшого размера датасета модель фокусировалась на последнем пасе, поэтому было принято решение построить 2 модели: в первой обучаться на всей последовательности и смотреть вклад исключительно последнего паса (на выходе получилась «контекстная» версия xA), а во второй обучаться на всех пасах, кроме последнего и смотреть их вклад. Как бы это не было удивительно, но вторая модель в итоге сошлась немного лучше, хотя для серьезных выводов необходим датасет значительно большего размера.
Техническая часть
Классификатор должен учитывать весь контекст атаки, то есть все пасы, но должен уметь их отличать, чтобы потом оценить их влияние. Учитывая все потребности, была выбрана архитектура рекуррентной нейронной сети. Ее преимущество как раз в том, что она хорошо работает с последовательностями, например, часто применяется в работе с текстом (последовательность слов) и звуком (последовательность фреймов) в задачах классификации, машинного перевода, проверки орфографии, распознании речи и тд.
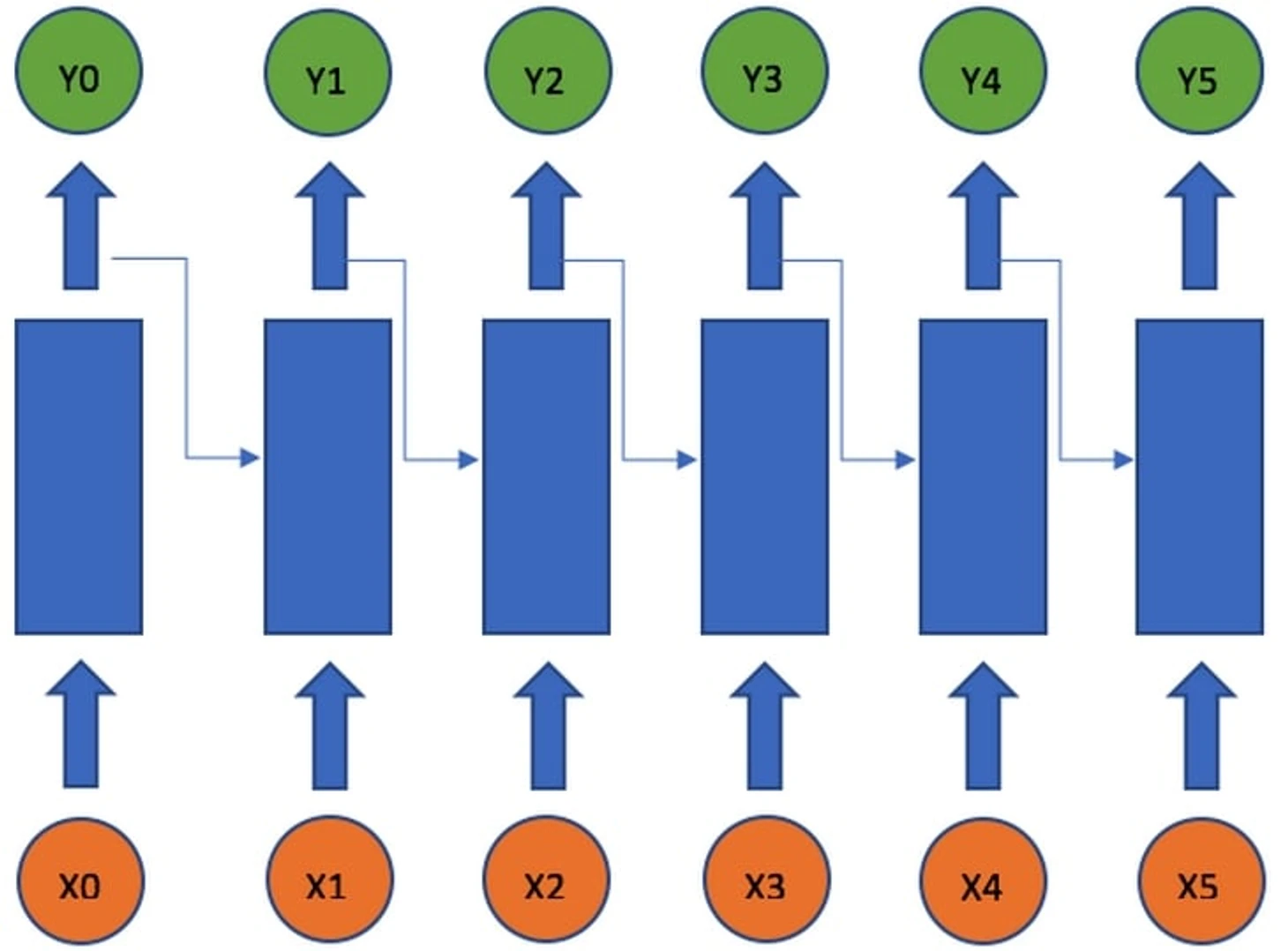
На картинке выше последовательность Xi – набор входных векторов (в нашем случае – вектора пасов из одной атаки), Yi – набор выходных векторов (в нашем случае это будет вектор размерности 2 для определения исхода атаки). Также нам понадобится только последний Y, который как раз будет отвечать за предсказание исхода. Синий ящик здесь – это и есть сама нейронная сеть. Рекуррентной архитектура называется потому, что через один синий ящик проходят все элементы последовательности, однако, кроме входного вектора Xi на каждом шаге модель получает выход из предыдущего шага – Yi-1 (на первом шаге обычно вместо него на вход подается нулевой вектор той же размерности), таким образом модель учитывает контекст предыдущих элементов. На деле у этой архитектуры есть проблемы с длинными последовательностями, поэтому используется ее немного усложненная версия – LSTM. Подробно на ней я останавливаться не буду, но принцип работы у нее тот же.
Для оценки вклада каждого паса использовались Shap values – техника, названная в честь американского математика Шэпли, с помощью которой можно залезть под капот нейронной сети. Этот метод основан на теории игр и последнее время становится достаточно популярным. Я ограничусь ссылкой на отличную русскоязычную статью (в комментариях) о нем и примером с визуализацией (из той же статьи):

На рекуррентных сетях визуализация не будет такой красивой, но, по сути, на выходе каждому вектору паса будет присвоено значение SHAP, которое будет отражать влияние этого паса на позитивный исход.
Подробнее о данных
Открытые данные StatsBomb по пасам хранятся в формате таблицы с большим количеством полей для каждого паса. Нам нужны будут не все, ограничимся набором из:
data_col = [‘start_location_x’, ‘start_location_y’, ‘end_location_x’, ‘end_location_y’, ‘height’, ‘length’, ‘angle’]
labels_col = [‘shot_assist’]
types_col = [‘play_pattern’]
Первый список отвечает конкретно за описание паса, второй – это target, который модель будет в дальнейшем предсказывать. Третий список нам напрямую не нужен, но, благодаря значениям в колонке play_pattern я разделял набор из всех пасов на разные атаки. На этом моменте остановимся поподробнее. Play pattern – это тип атаки, в которой выполнялся пас, которому присвоен этот паттерн. StatsBomb выделяет 8 паттернов, подробное описание которых можно найти здесь (в комментариях) (стр. 10). Да, изначально кажется, что банально просто использовать поле possession_team и разделять атаки при изменении этого параметра. Но этот подход не сработает в случаях, когда обороняющаяся команда делает перехват и выносит мяч / отдает неточный пас, таким образом не сохраняя владение. Так что считается, что атака первой команды не прерывалась. Именно поэтому был выбран подход с разделением пасов на атаки при помощи паттернов атаки. Таким образом, атака разделяются при изменении в поле play pattern. Да, из-за этого подхода возникают ситуации, когда пасы игроков из разных команд (правда, максимум, двух))) оказываются в одной атаке. В следствие чего при определении влияния пасов на результат необходимо ввести проверку на соответствие пасующего игрока команде, проводящей атаку.
В итоге у нас каждый пас в атаке описан вектором из 7-и чисел (см data_col), желательно, нормализованных по направлению атаки и размерам поля. Далее, для последнего паса в атаке запоминаем значение поля shot_assist. Теперь имеет смысл посмотреть еще раз на иллюстрацию рекуррентной нейронной сети и представить, как наши вектора предстают Xi. Последовательность Yi в таком случае будет показывать абстрактное представление пространства результата. После прохода всей последовательности через рекуррентный слой, последний выходной вектор Yk с помощью линейного слоя приводится к размерности 2 (для бинарной классификации).
После обучения на месси данных, с помощью библиотеки shap вычисляются значения «влияния» для каждого паса (учитывая проверку тремя абзацами выше) в датасете по Чемпионату мира.
Сейчас следует вспомнить о том, что речь шла о двух моделях. Принципиальной разницы нет, поэтому до этого момента я не заострял на этом внимание, чтобы никого не запутать. Как я уже писал, разница в обучении лишь в том, что во второй модели отбрасывается последний пас (но лэйбл shot_assist, конечно, остается). Более значимая разница в выборе пасов для определения SHAP значений – в первой модели значение вычисляется только для последнего паса (которого нет во второй), а во второй модели – для всех пасов.
Далее эти значения суммируются для каждого игрока (для обеих моделей) и формируются ранжированные списки для каждой модели.
Результаты
К сожалению, в отличие от предыдущего поста, модель не подразумевает красивой и наглядной визуализации, поэтому ограничусь лишь ранжированными списками.
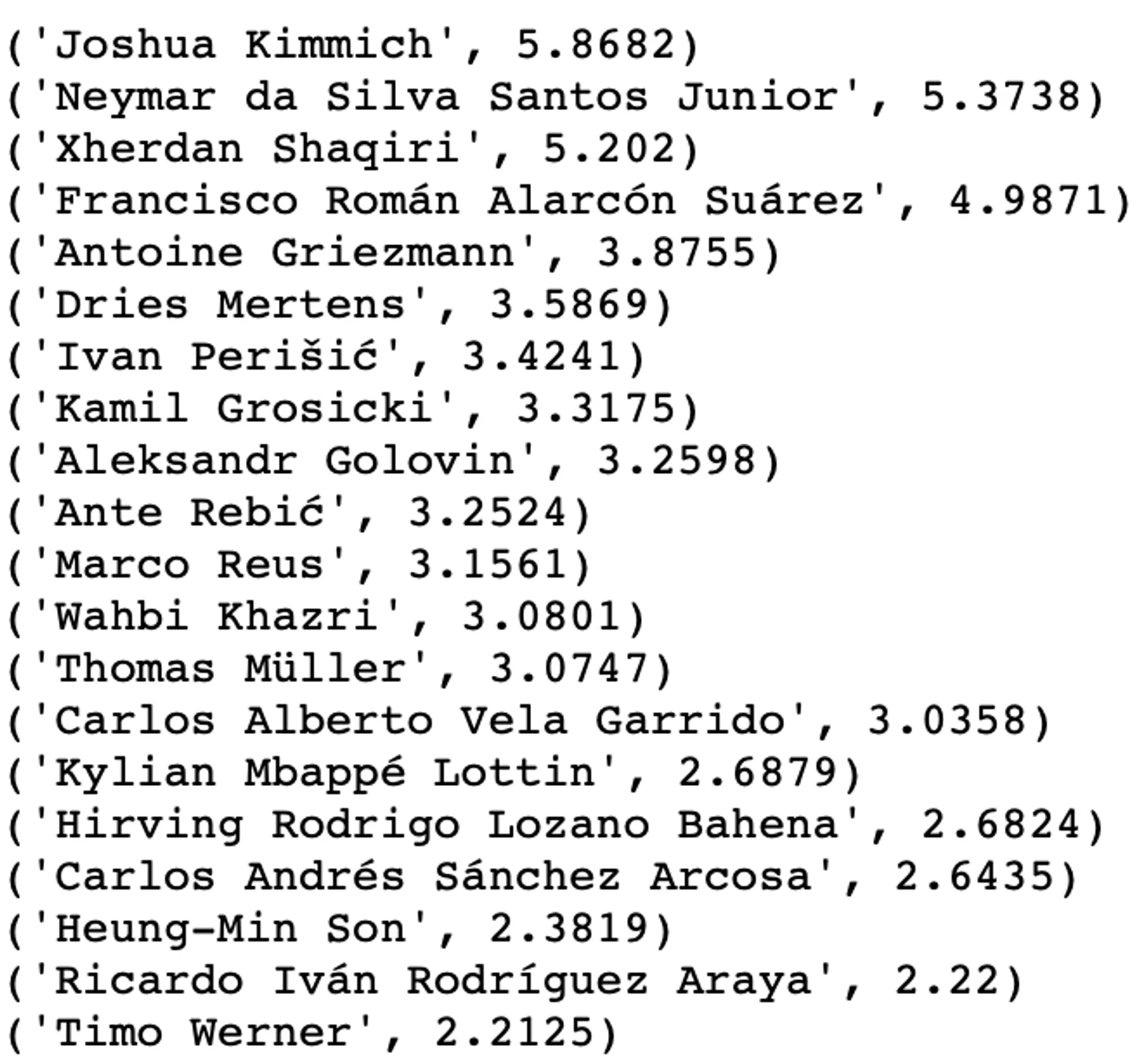
Топ-20 с суммой влияния первой модели (по последнему пасу):
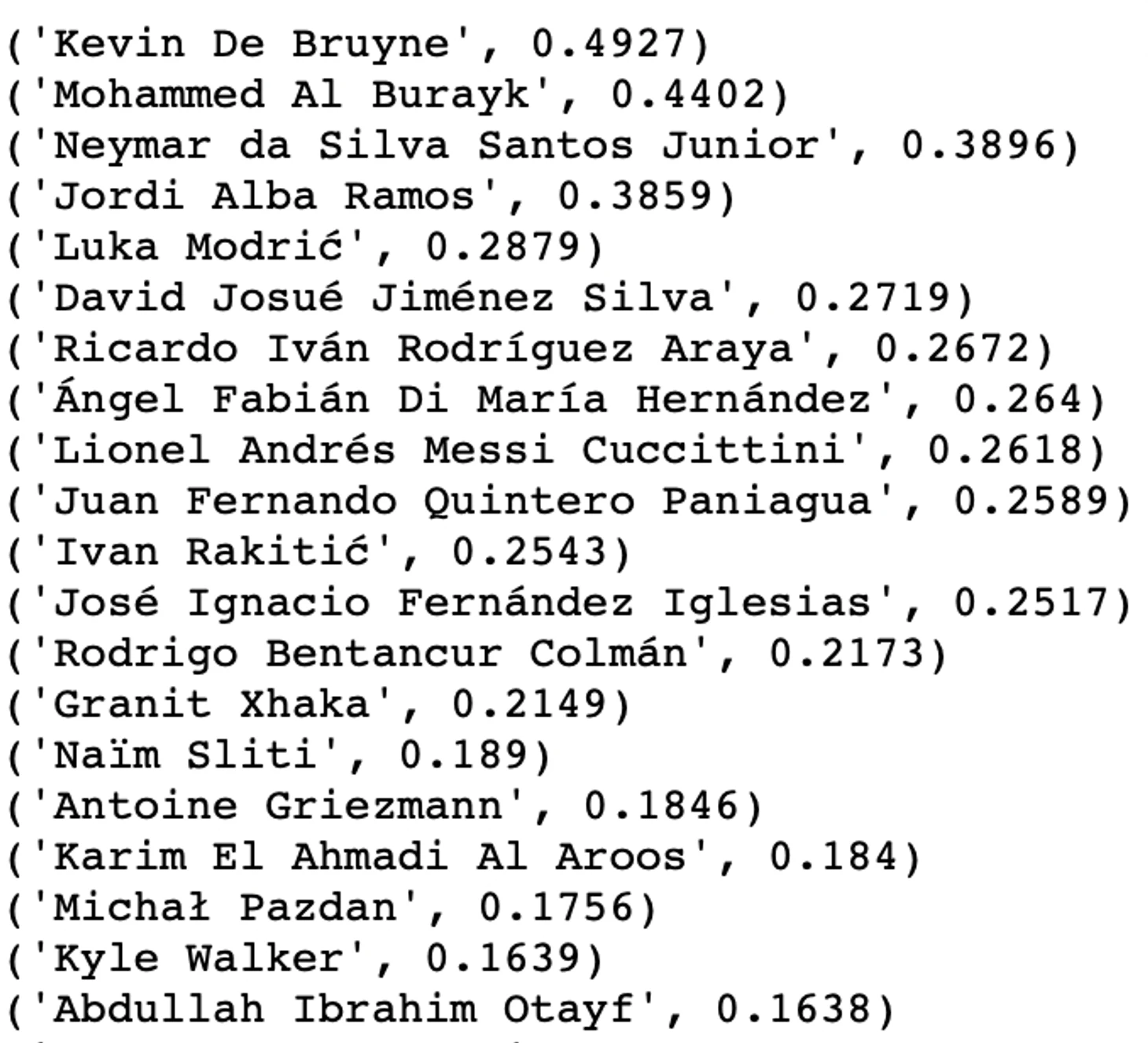
Топ-20 с суммой влияния второй модели (по всем, кроме последнего):
Вывод, варианты использования и перспективы
Конечно, в силу несбалансированности и небольшого размера датасета есть очень странные выбросы (хотя, как и в предыдущем посте, обе модели выделяют пасовые скиллы игроков Саудовской Аравии), но в целом, считаю эксперимент удачным.
Вариантов использования можно сходу придумать достаточно: как альтернативу (или вместе с) NSxG / passing uniqueness, можно разбить влияние игроков на зоны и посмотреть откуда конкретные игроки лучше созидают, оценивать общее качество атаки команды или даже посмотреть, насколько качественно команда атакует в тех самых play patterns и т.д.
Эта модель не выложена в репозитории, однако всем желающим с радостью отвечу на все вопросы и поделюсь кодом / обученной моделью.
Фото: Gettyimages.ru/Angel Martinez / Stringer


Комментарии
Ссылка на описание Play patterns: https://github.com/statsbomb/open-data/blob/master/doc/StatsBomb%20Open%20Data%20Specification%20v1.1.pdf
Чем хуже прямая статистика пасов под удар и голевых передач?
В топе будут в основном те же люди, что и в этих таблицах.