
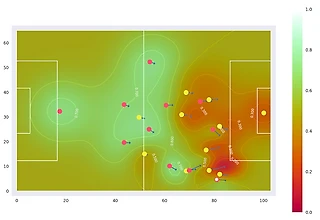
Последнее время стали часто выходить интересные исследования на тему оценки чего-либо в футболе. xG и packing уже стали классикой: в основном, все понимают зачем нужны эти метрики и не бросаются в крайности по поводу их пользы. Сейчас обсуждаются xT, NPxG для оценки атакующего влияния и PATCH (или другие метрики, основанные на построении диаграммы Вороного) для обороны. Недавно на конференции Sloan вышло абсолютно прорывное исследование Decomposing the Immeasurable Sport (ссылка в комментариях), которое объединило в себе несколько лучших пасовых метрик и предыдущую работу автора по оптимальному выбору позиции. Если вкратце, то модель для каждого момента времени выводит число от -1 до 1, показывающее вероятность забить (или пропустить) в текущем владении.

Визуализация из оригинальной статьи
Скорее всего этот подход станет классическим, но вряд ли этого стоит ждать скоро, потому что для обучения и работы с моделью необходимы трекинговые данные в огромном количестве.
Откуда берутся трекинговые данные
Для начала стоит объяснить что это такое и чем эти данные отличаются от обычных. Обычные данные называются Event data и формируются благодаря записи каждого действия в матче. То есть такой датасет, грубо говоря, состоит из описания каждого касания мяча. Разница между компаниями, предоставляющими эти данные в том, как касания описываются и интерпретируются. Например, все по-разному оценивают сиквенсы (сиквенс - более абстрактное определение владения - не все сиквенсы являются владениями, некоторые владения могут делиться на сиквенсы).
Трекинговые данные отличаются и по тому, как их собирают, и по способу хранения. В этом случае описываются не касания мяча, а временные метки - чем подробнее, тем лучше. То есть это, по сути, является дискретизацией происходящего на поле.
Собирать такие данные намного сложнее, особенно вручную, но они дают возможность оценивать и учитывать значительно более сложные вещи. Например, как раз то самое исследование про выбор позиции игроков от Luke Bornn.
Есть два способа получать трекинговые данные:
Отмечать руками с помощью специального ПО - тяжелая и долгая работа, сложно воспроизводить в режиме реального времени. Из компаний, которые так делают, возможно, Опта, но я не готов утверждать, потому что не нашел у них никаких упоминаний о том, как они собирают трекинговые данные. Обычно, компании, применяющие продвинутые технологи об этом очень явно говорят.
Обучить object detection модель для определения координат игроков на записи матча.
Остановимся на втором случае
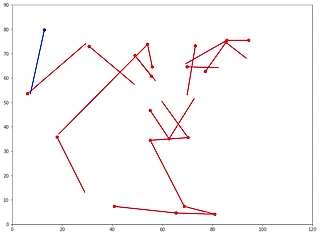
Преимущества такого подхода очевидны: скорость работы и финансовые затраты (не нужно нанимать кучу людей, размечающих матчи), предсказуемая точность, не зависящая от человеческого фактора. Есть и сложности: нужна размеченная база, чтобы на ней обучить модель или нужно допилить существующие модели детектирования объектов.

Изображение из сайта scisports.com
Прямо сейчас есть (минимум) четыре компании, делающие такой продукт:
Stats Perform - большая компания, собирающая данные для многих видов спорта; среди клиентов PSG и Chelsea.
Metrica Sports - стартап из амстердама, который, по-моему, продвинулся максимально далеко в своих разработках; среди клиентов Valensia и Toronto.
Scisports - тоже интересный стартап, возможно, самый открытый в плане своих технологий; среди клиентов Leeds, Ajax, OL, VITESSE, сборная Бельгии.
Arqam - наименее понятный стартап из Египта, который купила компания Statsbomb несколько месяцев назад. Отмечают, что их сервис предоставляет в 2 раза больше данных за каждый матч, чем любой из конкурентов.
У всех основной продукт - данные, которые они собирают благодаря своим технологиям. Также, часть из них делает свои приложения с визуализациями разной степени углубленности. В первом случае данные предоставляются клубам для серьезной аналитики. С приложениями же, скорее всего, работают тренеры или видеоаналитики.
Перспективы
Применение ии в сборе данных и последующем анализе - шаг вперед для футбольной индустрии, однако это только начало. Я считаю, что будущее за end2end моделями, которые не просто готовят данные для дальнейшего анализа, а делают нужные выводы, основываясь непосредственно на видеозаписи. Скорее всего, компании будут предоставлять более сложный анализ для клубов по их запросам или, в идеале, клубы будут получать предобученные модели для тренировки под конкретные задачи.
Теперь, в качестве дешевой иллюстрации, я покажу свою модель, натренированную на определение play pattern по видеозаписи матча из мобильной версии футбольного менеджера 2019.
Для своего эксперимента я сделал запись экрана двух матчей Football Manager 2019 mobile и разбил на записи длиной в секунду. Далее в отдельный файл для каждой секундной записи написал play pattern своей команды. Play patterns: build_up, pos_defence, stand_defence, clear, mid_press, pos_attac, high_press, stand_attac, corn_defense, counter, corn_attac.
В следующем этапе каждая секундная запись преобразовывалась в последовательность кадров, каждый кадр проходил через небольшую предобработку (уменьшение качества и размера, обрезание ненужной части - трибун и пространства за воротами).

Пример 3-х кадров из одной записи. Моя команда - красная, на кадрах запечатлена часть билдапа
Нейронная сеть состояла из двух сверточных, одного рекуррентного (далее - рнн) и двух линейных слоев. Идея в том, чтобы на каждом шаге в модель подавалась последовательность кадров из одной секунды записи, из этих кадров автоматически выделяются признаки (благодаря свертке) и подаются в рнн (подробнее я описал работу этой архитектуры в предыдущем посте). Благодаря двум линейным слоям выход рнн уменьшается до размера, совпадающего с количеством классов (play patterns). Задача модели при обучении - максимизировать значение в ячейке, номер которой совпадает с номером play pattern.

Архитектура нейронной сети
Теперь для любой записи матча футбольного менеджера можно для каждого момента времени определять тип игры. Это, конечно, можно перенести на реальный футбол. Нужно больше размеченных данных и более глубокая сеть. Так же можно перевести в end2end формат многие существующие метрики. Например те же paking и семейство моделей с ожидаемыми значениями, что должно дать прирост в точности и объективности предсказаний. Естественно, более сложные модели вроде определения качества выбора позиции игроком тоже переносится в этот формат.
Как обычно, ссылки на код и упомянутые статьи помещу в комментариях. И с радостью отвечу на все вопросы.

Комментарии
Статья про EPV: http://www.sloansportsconference.com/wp-content/uploads/2019/02/Decomposing-the-Immeasurable-Sport.pdf
Статья про выбор позиции: http://www.lukebornn.com/papers/fernandez_ssac_2018.pdf
Насчёт барсы слышал что-то похожее, а про опту шёл от противного)