Gen-AI в футбольном скаутинге: эволюция, практика и перспективы

Введение
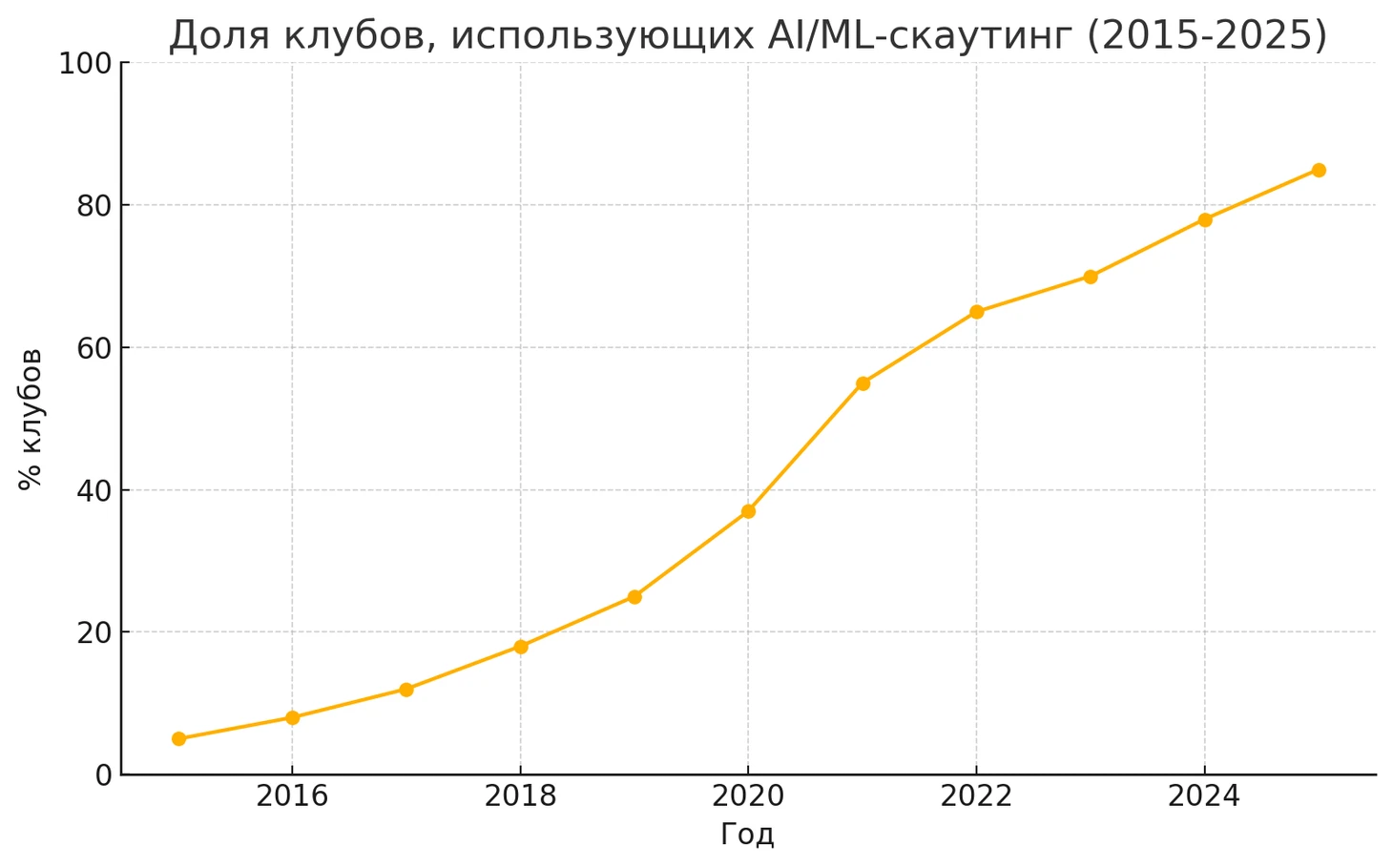
Футбольные клубы все активнее обращаются к технологиям искусственного интеллекта (ИИ) в скаутинге, стремясь получить конкурентное преимущество на трансферном рынке. В условиях растущей глобализации футбола и финансового давления традиционные методы поиска талантов перестают быть достаточно эффективными. Ежегодно совершаются десятки тысяч трансферов по всему миру – так, в 2024 году было зарегистрировано рекордное число 78 742 международных переходов игроков.
Обработать такой объем информации вручную практически невозможно, поэтому клубы инвестируют в автоматизированный анализ данных. Финансовый фактор также играет значительную роль: даже топ-клубы с доходами под €900 млн могут завершать сезон с убытками (пример – чистый убыток €91 млн у одного из европейских лидеров в сезоне 2023/24, даю подсказку клуб из Испании).
В этих условиях правильная селекция «стоимость-качество» становится вопросом выживания. Концепция «Moneyball» (поиск недооцененных игроков на основе статистики) из бейсбола наглядно показала, как аналитический подход снижает затраты и дает результат. Это вдохновило футбольные клубы пересмотреть свои методы: вместо одной интуиции скаутов теперь решения подкрепляются объективными метриками и моделями. В итоге, ИИ-скаутинг призван снизить роль человеческого фактора, минимизировать ошибки при дорогостоящих трансферах и обнаруживать «скрытые сокровища» раньше конкурентов.
Ускоренное развитие цифровых технологий и доступность данных о матчах стали ключевыми драйверами изменений. Современные команды собирают гигантские массивы сведений: детализированную матчевую статистику, показатели GPS-трекеров, видео каждого эпизода, отчеты скаутов, новости и даже посты игроков в соцсетях. Такая «датизация» футбола создает новое сырье для анализа, а последние достижения в области машинного обучения позволяют извлечь из этих данных ценную информацию.
Уже к концу 2010-х анализ данных прочно вошел в футбольный менеджмент: от топ-клубов до полупрофессиональных команд. Например, скромный английский клуб «Летерхед» еще в 2019 году заключил партнерство с «IBM Watson» для анализа отчетов матчей и даже контента из «Twitter» в подготовке к играм. Этот пример показывает, что ИИ-инструменты стали достаточно доступными, чтобы ими могли пользоваться не только гранды, но и небольшие команды.
В последние годы на смену простым статистическим отчетам приходят продвинутые методы ИИ – в том числе генеративный ИИ. Если раньше упор делался на цифры (голы, передачи, % брака) и простые модели, то теперь клубы осваивают встраивание данных в векторы (embeddings) и кластеризацию для группировки игроков по стилям, а также применяют большие языковые модели (LLM) для работы с неструктурированными текстами. Переход от классического «eye-test» (визуальной оценки игрока скаутом) к данным происходил поступательно. Сначала появились расширенные метрики (например, передачи под удар, ключевые передачи, % выигранных единоборств), затем – метрики качества моментов вроде ожидаемых голов (xG) и ожидаемых голевых передач (xA), дающие более точную оценку вклада игрока.
Далее в арсенал добавились методы машинного обучения: модели начали учиться на исторических данных прогнозировать развитие карьеры футболиста или его адаптацию к более сильной лиге. Появилась возможность представлять футболиста как точку в многомерном пространстве характеристик – так называемый embedding – что позволяет сравнивать и искать схожие профили вне зависимости от позиций. Кластеризация по этим эмбеддингам группирует игроков по типам: к примеру, можно обнаружить скрыто схожих по стилю крайнего защитника и полузащитника, которых традиционная классификация разделяла бы. Примером такого подхода служит английский клуб «Брентфорд», использующий кластерный анализ для выявления недооцененных игроков с нужными командными характеристиками.
Новейший этап эволюции – внедрение генеративных моделей ИИ в скаутинг. Генеративный ИИ (как разновидность больших языковых моделей) умеет понимать и порождать связный текст, что открывает новые возможности для футбольной аналитики. Теперь нейросеть может прочесть тысячи страниц скаутских отчетов и выдать краткую сводку или даже ответить на сложный вопрос о перспективах игрока в заданной системе.
Английская Футбольная Ассоциация (The FA) недавно начала экспериментировать с такой технологией: исторические отчеты скаутов были загружены в платформу «Google Vertex AI», где LLM суммирует их и выделяет ключевые моменты развития каждого молодого игрока . Это позволяет мгновенно получить «резюме» по игроку – основной вывод о его прогрессе, сильных и слабых сторонах – без необходимости прочитывать десятки разрозненных документов. Таким образом, за последние два десятилетия футбольный скаутинг прошел путь от бумажных блокнотов к облачным данным и ИИ-алгоритмам, а сейчас вступает в эру генеративного ИИ, обещающего еще больший охват информации и скорость анализа.
История: от статистики и «глаз алмаза» к ML и LLM
Исторически скаутинг опирался на личные наблюдения и субъективное мнение селекционеров. Традиционный скаут «старой школы» объезжал бесчисленные матчи в низших лигах в поисках таланта, делая пометки в блокноте. Показатели учитывались самые базовые – голы, передачи, антропометрия игрока, иногда примитивная статистика вроде среднего рейтинга за матч. Такой подход открыл многих легендарных футболистов, но, естественно, зависел от интуиции и был подвержен предвзятостям и ошибкам восприятия. Например, скоростной форвард мог произвести впечатление на скаута несколькими яркими эпизодами, хотя объективно его эффективность была низкой. Или наоборот – талантливый игрок из «нефутбольной» страны мог быть проигнорирован, потому что у клуба не было там своих агентов.
Постепенно клубы начали понимать ценность объективных данных. Первым звоночком стала революция «Moneyball» в бейсболе (начало 2000-х): генменеджер «Окленда» Билли Бин начал отбирать игроков не по отчетам скаутов, а по необычным статистическим показателям, свидетельствующим об их недооцененности. Успех «Moneyball» в «MLB» привлек внимание футбольных функционеров.
В европейском футболе пионерами статистического подхода стали такие люди, как Дамиен Комолли (в «Ливерпуле» и «Тоттенхэме») и Мончи (в «Севилье»), которые еще в 2000-х формировали базы данных игроков и искали «изыски», опираясь на цифры. Появились первые компании, специализирующиеся на футбольной статистике: Opta Sports, Wyscout, InStat и др. К 2010-м годам клубы АПЛ и других топ-лиг начали нанимать аналитиков и заводить собственные базы данных игроков с метриками. Например, «Арсенал» еще в 2012 году приобрел статистическую фирму StatDNA, чтобы получать эксклюзивную аналитику.
Следующим этапом стал анализ продвинутых показателей и больших данных. С распространением позиционного трекинга (GPS и оптических систем) команды получили точные цифры по пробегу, спринтам, расположению игроков. Появились сложные метрики эффективности: expected goals (ожидаемые голы, xG), expected assists (xA), индексы наподобие «SciSkill» от «SciSports», оценивающие текущий и потенциальный уровень игрока. Анализ стал более научным: клубы искали корреляции и шаблоны в данных, ранее скрытые от глаза.
К примеру, британские исследователи выяснили, что до 30–40% голов приходят со стандартов, но доля тренировочного времени на стандарты была несоразмерно мала. Такая информация привела к тому, что датский клуб «Мидтьюлланд» начал уделять бешеное внимание розыгрышам угловых и штрафных, наняв штатного «тренера по стандартам». Результат – в одном из сезонов почти 49% своих голов «Мидтьюлланд» забил со стандартных положений, что принесло клубу чемпионство в Дании. Этот пример иллюстрирует переход от интуитивного понимания к решениям на основе данных: цифры подсказали нишу, которую можно эксплуатировать.
Параллельно росли и базы данных по игрокам всего мира. Если раньше клуб средней руки мониторил десяток стран через сеть скаутов, то теперь есть возможность охватить практически каждый уголок земного шара. Платформы скаутинга стали неотъемлемым инструментом: так, Wyscout и InStat предоставляют видео и статистику по сотням лиг, а сервисы вроде SciSports агрегируют данные по сотням тысяч футболистов. Это означало, что теперь можно обнаружить талант в условной Второй лиге Перу или чемпионате Вьетнама, даже не выезжая в командировку – достаточно цифр и нарезок видео. Однако обилие информации породило новую проблему: как отделить значимое от шумового. Тут на авансцену и вышли методы машинного обучения.
Машинное обучение (ML) позволило автоматизировать поиск закономерностей там, где человеку сложно обработать все комбинации факторов. Примерно с середины 2010-х годов клубы начали строить ML-модели для решения типичных задач скаутинга: оценки потенциала игрока, прогнозирования его статистики при переходе в другую лигу, сравнения игроков между собой. Первые модели были относительно простыми (например, регрессии, оценивающие, как игрок из «Чемпионшипа» проявит себя в АПЛ по совокупности показателей).
Но со временем стали применяться и более сложные алгоритмы: деревья решений и градиентный бустинг (вроде XGBoost) для ранжирования игроков по перспективности, нейронные сети для поиска нелинейных зависимостей, графовые нейросети (GNN) для анализа игровых взаимодействий. Появился термин «технический скаутинг» – то есть поиск игроков с нужными характеристиками с помощью алгоритмов, а не через просмотры матчей.
К концу 2010-х машинообученческие модели стали неотъемлемой частью скаутских отделов топ-клубов. Например, «Ливерпуль» при Юргене Клоппе использовал аналитический отдел во главе с Ианом Грэхэмом, который применял модели для оценки трансферных целей – так были выбраны Эндрю Робертсон и Мохамед Салах, чьи статистические профили идеально соответствовали стилю команды.
«Брентфорд» и «Мидтьюлланд» под руководством Мэтью Бенхэма создали собственные аналитические pipeline-ы: сотни тысяч игроков со всего мира фильтровались по данным и делились на 16 игровых амплуа (у «Брентфорда» своя система градаций позиций, например, левый вингер «классический» и левый вингер «инвертированный»). Затем алгоритмы и скауты совместно сужали списки и находили оптимальные кандидатуры на каждую позицию.
Уникальность данных стала важным фактором: как отмечал технический директор «Брентфорда» Ли Дайкс, клуб использует собственные проприетарные данные от компании Smartodds Бенхэма, что дает им преимущество, ведь многие соперники пользуются одинаковыми сторонними метриками. Иными словами, когда все прочитали одни и те же отчеты Wyscout, «маржинальная выгода» есть у того, кто накопал дополнительную инсайдерскую информацию или построил свою модель рейтинга.
Последнее достижение в исторической эволюции –интеграция больших языковых моделей (LLM). Если предыдущие шаги касались числовых данных, то LLM позволили взяться за текстовую информацию, которая ранее практически не структурировалась автоматикой. Скаутские департаменты имеют десятки тысяч страниц описаний игроков, отчетов о характере, интервью, медицинских заключений и т.д. Теперь появилась возможность «скормить» все эти тексты модели вроде BERT или LLaMA, чтобы она извлекла смысл и ответила на вопросы. Генеративный ИИ способен не только анализировать, но и генерировать связный текст – например, скаутский отчет в удобном формате или сравнительный профиль двух игроков.
В 2023–2024 гг. сразу несколько пилотных проектов продемонстрировали потенциал LLM в футболе. Помимо упомянутого примера с FA и Google (генерация сводок по отчетам) есть кейс в испанской Ла Лиге: «Севилья» совместно с IBM внедрила систему Scout Advisor на базе Watson. Эта платформа позволяет спортивному директору Виктору Орте задавать поисковый запрос на естественном языке (например, «extremo con desparpajo» – «скоростной вингер») и мгновенно получать список кандидатов с автоматическим резюме по каждому из сотен скаутских отчетов.
Орта отмечает, что за 2 минуты получает информацию, ради которой раньше пришлось бы читать 45 отчетов. Таким образом, LLM-анализ экономит время и сглаживает субъективность отдельных скаутов, выдавая консолидированное мнение из массива наблюдений. Можно сказать, что с приходом генеративного ИИ скаутинг вступил в новую фазу, где человек получает персонального ассистента, способного в считанные секунды проанализировать знания, накопленные клубом за многие годы.
Современная практика: кейсы «Брентфорда», «Мидтьюлланда», «Валенсии» и др.
Практические примеры внедрения AI в скаутинге варьируются от богатых клубов АПЛ до небольших команд и национальных федераций. Одним из самых известных кейсов является успех небольших клубов, применивших data-driven подход для конкуренции с грандами.
«Брентфорд» – яркий пример «Moneyball» в футболе. Этот клуб с ограниченным бюджетом смог дважды подняться в Чемпионшип, а затем в 2021 году – выйти в Премьер-лигу, где уверенно закрепился, обыгрывая порой топ-команды. Секрет – в использовании аналитики и машинного обучения при отборе игроков. Владелец «Брентфорда» Мэтью Бенхэм (бывший трейдер) внедрил культуру решений на основе данных: клуб просеивает базу из ~85 500 потенциальных игроков (практически весь мировой пул) по заданным критериям на 16 специализированных позиций. Автоматический фильтр по метрикам (скорость, процент успешных отборов, xG, xA, выносливость и т.д.) сочетается с отчетами скаутов в регионах.
Затем следуют несколько этапов: скауты-лидеры по каждому региону отбирают топ-4 кандидата на позицию, аналитический отдел сравнивает их показатели, тренерский штаб дает свое заключение и в итоге формируется шорт-лист приоритетных целей. За счет такого системного подхода «Брентфорд» находит недооцененных «самородков» раньше конкурентов. Например, Иван Тони был куплен из низшей лиги за £5 млн после того, как модели показали его высокую эффективность в Лиге 1 (24 гола за сезон) на фоне скромной цены. В АПЛ Тони вскоре стал одним из лучших нападающих, а в 2023 году был продан за сумму порядка £40 млн – колоссальная отдача на инвестиции.
Подобных историй много: Нил Мопе (взят из «Сент-Этьена» за €2 млн, забил 41 гол за 2 сезона и продан в «Брайтон» за €20 млн ), Олли Уоткинс (переквалифицированный из вингера в форварды, куплен за £1,8 млн – продан в «Астон Виллу» за £30+ млн) и др. Data-подход позволил «Брентфорду» формировать конкурентоспособный состав с минимальными затратами, оставаясь прибыльным на трансферном рынке. Кроме того, команда извлекла выгоду из статистики в тактике: известен факт, что аналитик прямо на скамейке в дни матчей подсказывает тренеру Томасу Франку на основании данных, как реагировать на ход игры (например, усиливать прессинг, использовать определенные зоны). Таким образом, «Брентфорд» встроил аналитику во все этапы – от селекции игроков до принятия решений по ходу матчей – и добился успеха, соревнуясь с клубами, чей бюджет в разы больше .
Еще один родственный кейс – датский клуб «Мидтьюлланд», которым также владеет Бенхэм. Здесь data-driven модель опробовали раньше, с середины 2010-х. «Мидтьюлланд» применял углубленный анализ статистики скандинавских лиг и смарт-скаутинг в Африке и Азии, что позволило приглашать талантов, незаметных для конкурентов. Получив от Smartodds доступ к базе игроков по всей Европе и миру, клуб начал анализировать производительность футболистов по нестандартным метрикам – например, «создание моментов» и «качество кроссов» – чтобы выявлять перспективных игроков, не попавших на радары больших клубов.
Комбинация алгоритмов и работы скаутов дала синергетический эффект, который спортивный директор Свенд Граверсен назвал «лучшее из обоих миров». Результат не заставил ждать: уже в первый полный сезон Бенхэма (2014/15) «Мидтьюлланд» впервые стал чемпионом Дании, затем повторил успех в 2018 и 2020. Клуб вышел на групповой этап Лиги Чемпионов – небывалое достижение для провинциальной команды.
Пример конкретного use-case: скаутская программа «Мидтьюлланда» обнаружила молодого вингера Пионе Систо, проанализировав данные его выступлений за юношеские команды (дриблинг, успешные обводки, влияние на xG команды). Систо был подписан и стал одним из лидеров команды, позже его продали с прибылью. Также клуб систематически применял данные для улучшения стандартов (как упоминалось, почти половина голов была забита со стандартных положений благодаря детальному анализу слабостей соперников на «втором этаже»). Опыт «Мидтьюлланда» показал, что даже на небольшом рынке инвестиции в аналитиков и ИИ-алгоритмы окупаются спортивными результатами. Неудивительно, что успехи датчан вдохновили другие средние клубы по всей Европе последовать их примеру.
На другом конце спектра – более традиционные клубы из топ-лиг, которые начинают интегрировать ИИ, чтобы не отстать от инноваций. «Валенсия» – пример команды с богатой футбольной историей, переживающей финансовые трудности в последние годы, которая обратилась к AI-решениям для повышения эффективности трансферов. Валенсийцы несколько сезонов подряд балансируют на грани бюджета и вынуждены продавать лидеров, поэтому поиск «выгодных сделок» для них жизненно важен.
В 2020 году «Валенсия» заключила партнерство с испанской AI-компанией Olocip, основанной бывшим футболистом Эстебаном Гранеро. Платформа Olocip предоставляет прогнозирующую аналитику: с помощью ML-моделей оценивает, как изменится результативность игрока при переходе в новую команду, прогнозирует его статистику на 2–3 года вперед с учетом возраста, стиля команды и лиги. По сути, Olocip предлагает взгляд «в будущее» игрока, тогда как классический скаутинг смотрит в прошлое.
Например, если клуб рассматривает двух нападающих, платформа может предсказать, что у 30-летнего форварда показатели в следующем сезоне просядут (из-за возраста и смены лиги), а у 24-летнего из менее сильного чемпионата, наоборот, вырастут при переходе – даже если сейчас их цифры сравнимы. Это помогает сделать выбор в пользу более перспективного приобретения. Кроме того, Olocip может советовать по продлению контрактов: модель, оценив динамику формы игрока, подскажет, не станет ли ветеран играть хуже, и стоит ли продлевать контракт на предлагаемых условиях. По сообщениям клуба, сотрудничество с Olocip позволило «Валенсии» снизить долю неудачных трансферов и более обоснованно подходить к переговорам с игроками и агентами.
Еще один свежий кейс – уже упомянутая «Севилья», внедрившая генеративный ИИ в скаутинг. Клуб известен своим сильным отделом селекции (спортивный директор Мончи славился умением находить звезд дешево), и теперь эта философия дополнилась возможностями LLM. Scout Advisor на базе IBM Watson используется скаутским отделом «Севильи» для обработки огромного массива внутренних данных – более 200 000 скаутских отчетов накоплено в базе! Ранее этот ценный контент зачастую оставался неструктурированным архивом. Теперь же LLM анализирует все эти тексты и позволяет задавать сложные запросы на родном языке, чтобы получить список релевантных кандидатов. Фактически, это превращает многолетний коллективный опыт скаутов в базу знаний, доступную через простое текстовое поле. Как отмечает спортивный директор «Севильи», теперь решение, на просмотр кого из игроков слетать, принимается не вслепую, а подкреплено мгновенным срезом всей имеющейся информации. Это особенно полезно в сжатые сроки трансферных окон, когда надо быстро оценить длинный шорт-лист.
Помимо клубов, AI-инструменты берет на вооружение и национальные федерации. Например, Английская федерация футбола (The FA) использует облачные технологии Google не только для хранения данных, но и для анализа отчетов скаутов о юных игроках по всей стране. Цель – с помощью ИИ выделить таланты, которые могут усилить сборные Англии разных возрастов. Генеративные модели помогают выявлять из текста отчетов скрытые нюансы – например, характеристики личности игрока или прогресс в обучении – и сравнивать их по всей выборке. Таким образом, ИИ ускоряет процесс отбора «бриллиантов» из тысячи юных футболистов, формируя рекомендации тренерам сборных.
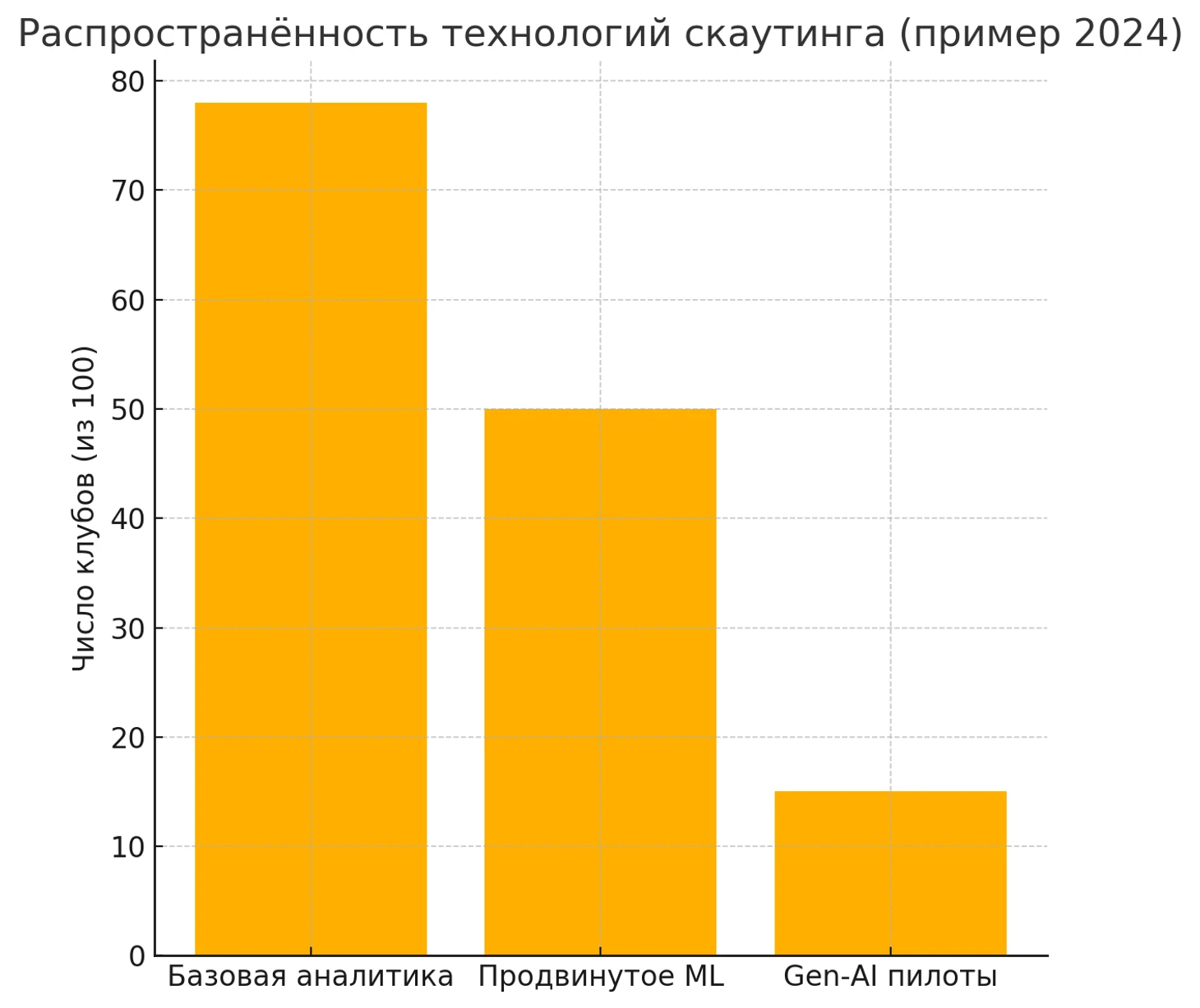
Конечно, основой современного AI-скаутинга остаются платформы данных. Крупнейшая из них – Wyscout (входит в Hudl) – давно стала стандартом индустрии для селекционеров. Она содержит видеонарезки и статистику более чем по 600 лигам и турнирам по всему миру и свыше 500 000 профилей игроков. Скауты могут фильтровать игроков по десяткам параметров (позиция, возраст, рост, контрактный статус, ключевые статистические показатели) и сразу просматривать видео всех действий выбранного футболиста.
SciSports предлагает более продвинутую аналитику: помимо базы из 240 000+ игроков из 250+ лиг, их платформа Recruitment оценивает каждого с помощью собственного показателя SciSkill (текущий уровень) и SciPotential (потолок роста), сравнивает игроков между собой и даже предсказывает рыночную стоимость трансфера с помощью ML-модели, обученной на данных 600 000 сделок. По сути, такие сервисы становятся для клуба внешним AI-ассистентом, который в режиме on-demand подскажет, кого из доступных на рынке игроков стоит рассмотреть, и сколько он может стоить. Даже агентства и игроки сами начинают пользоваться подобными инструментами: в SciSports отмечали, что их алгоритм востребован агентами при обосновании цены игрока перед клубом (например, чтобы доказать с помощью цифр, что клиент стоит запрашиваемую сумму).
Отдельного упоминания заслуживает поиск «бюджетных альтернатив» – типовая задача, решаемая ИИ. Когда клуб не может позволить себе звездного игрока, он пытается найти на рынке более дешевого футболиста с похожим набором характеристик (т. н. like-for-like replacement). В прошлом это было сродни искусству, а теперь ставится на поток. Например, если команда не в состоянии приобрести условного Н’Голо Канте для опорной зоны, она формирует через алгоритм профиль Канте (статистический «слепок» – per90 отборы, перехваты, радиус покрытия поля, точность передач) и ищет по базе игроков того, у кого показатели близки, но цена существенно ниже. Такой «бюджетный Канте» может играть в чемпионате Бельгии или Бразилии – и быть обнаружен с помощью кластеризации данных.
«Брайтон» славится именно таким подходом: например, эквадорец Мойсес Кайседо был приглашен в 2021 году за €5 млн из южноамериканского чемпионата на роль, аналогичную Канте, – скаутов убедили его феноменальные цифры по отборам и перехватам, а также зрелость игры в 19 лет. Спустя два года Кайседо раскрылся и был продан в «Челси» уже за более чем €110 млн, что стало рекордом АПЛ. Этот случай – один из многих, где алгоритм помог найти «игрока на вырост» на замену дорогой звезде, и клуб получил огромную прибыль. В таких успехах данные часто превосходят человеческий глаз: традиционные скауты скептически относились к худощавому опорнику из Эквадора, но цифры оказались правы.
Еще один интересный кейс – виртуальные селекционные дни через AI-платформы. Например, стартап AiSCOUT позволяет молодым игрокам со всего мира проходить стандартизированные тесты (навыки дриблинга, скорость, выносливость, прыжок и т.п.), снимая их на камеру телефона, а ИИ оценивает результаты и сопоставляет с эталонами. Клубы (в том числе «Челси» и «Бернли») сотрудничают с AiSCOUT, просматривая этих «виртуальных кандидатов». Так 18-летний Андре Одеку из низшей лиги получил шанс – алгоритм выделил его отличные физические показатели, и его пригласили на просмотр в молодежку «Бернли», где он сумел закрепиться. Этот пример демонстрирует, как ИИ расширяет географию скаутинга, убирая случайность из процесса «заметят/не заметят». Теперь шанс показать себя есть у каждого, у кого есть смартфон, а клубы благодаря ИИ отсеивают тысячи заявок в автоматическом режиме, экономя ресурсы.
Подводя итог по практике: ИИ и аналитика прочно вошли в скаутинг на всех уровнях. В топ-клубах созданы собственные аналитические отделы (от 5 до 15 человек, часто с аналитиками данных и разработчиками), средние клубы опираются на готовые платформы и услуги консалтеров (типа SciSports, SkillCorner, Twenty3), а малые клубы и вовсе кооперируются с университетами или используют общедоступные данные. Происходит смена роли селекционера: из искателя талантов-одиночки он превращается в пользователя аналитических систем, интерпретатора данных. Однако во всех случаях подтверждается мысль, что наибольшего успеха достигает совмещение человеческого опыта и ИИ-инструментов. Например, «Брентфорд» и «Мидтьюлланд» подчеркивают, что окончательное решение по трансферу всегда остается за человеком, просто теперь у него на руках несравнимо более полная и объективная информация.
Кроме того, начинает формироваться новая культура в футбольном сообществе, основанная на данных. Спортивные директора теперь обсуждают не только скаутские «байки», но и метрики. Агент может принести на встречу с клубом распечатку аналитического профиля своего игрока. Сами футболисты в академиях получают отчеты со своими показателями и работают над их улучшением. То есть ИИ-скаутинг влияет не только на подбор кадров, но и на образ мышления футбольных профессионалов в целом.

Технологии: модели, пайплайны, эмбеддинги, фичи
В основе современных AI-решений для скаутинга лежит целый стек технологий машинного обучения. Рассмотрим ключевые из них и то, как они используются.
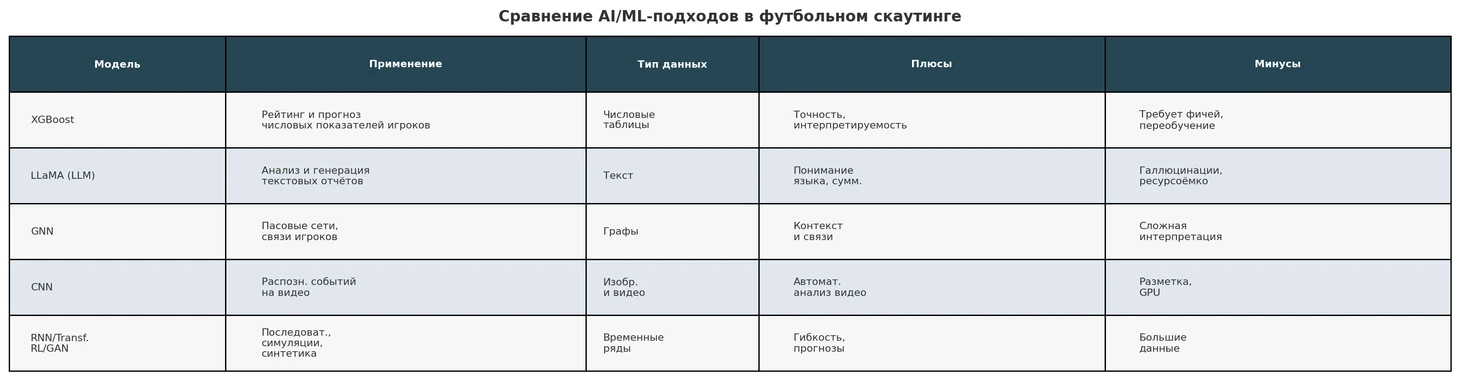
Модели NLP и LLM (BERT, LLaMA и др.). Для работы с текстовой информацией – отчетами, статьями, комментариями – применяются языковые модели. Например, BERT и другие трансформеры могут классифицировать текст (выявлять тональность отзыва о игроке, упоминания травм, сильных качеств) или выполнять поиск по большим текстовым базам. Их используют, чтобы автоматически сортировать скаутские отчеты или находить в них нужные сведения.
Более продвинутые LLM (вроде GPT-4 или открытой модели LLaMA от Meta*) способны на генерацию и диалог. Их начали обучать на специфичных данных: например, на базе футбольных отчетов и статей – чтобы модель разбиралась в футбольной терминологии и могла адекватно отвечать. IBM WatsonX – пример платформы, где лежит своя большая языковая модель, обученная на спортивных текстах. В «Севилье» через WatsonX делают запросы на испанском языке, и модель понимает их, потому что обучена на миллионах похожих фраз из отчетов.
В перспективе LLM могут автоматизировать написание скаутских отчетов: получая на вход сырые статистические и видео-данные о игроке, модель сможет генерировать связное описание его стиля и рекомендацию – по сути, сымитировать работу скаута-аналитика. Уже сейчас прототипы такой системы тестируются (например, один из английских клубов экспериментировал с генерацией коротких справок по игрокам U21 для своих скаутов).
Генеративный ИИ также хорош для суммирования: как мы отмечали, FA (Английский футбольный союз) применяет LLM для конспектирования длинных скаутских досье на игроков. При правильном контроле качества это значительно повышает оперативность принятия решений. Важный технический нюанс – необходимость встроить LLM в инфраструктуру данных клуба.
Прежде чем LLM начнет отвечать на вопросы, клуб должен оцифровать и загрузить в базу все свои текстовые данные. Для этого часто используются облачные хранилища и СУБД (например, BigQuery у FA для централизации всех данных скаутинга). Затем поверх них уже запускается сервис генеративного ИИ (Google Vertex AI, IBM Watson, OpenAI API и пр.), который обращается к этим данным. Такой поток данных (pipeline) гарантирует, что выводы LLM основаны на реальных внутренних данных, а не придуманны ею с нуля. В итоге языковые модели становятся своего рода «умной надстройкой» над данными клуба, превращая их из разрозненного архива в живую базу знаний.
Градиентный бустинг и ансамблевые модели (XGBoost, LightGBM и др.). Для анализа табличных данных (таблички со статистикой игроков, измерениями, атрибутами из FIFA/Football Manager и т.п.) широко применяются алгоритмы градиентного бустинга решающих деревьев (базы данных, если по-русски). XGBoost стал популярным благодаря успехам на соревнованиях по анализу данных: он эффективен, умеет выявлять нелинейные зависимости и работает даже с небольшими выборками. В скаутинге XGBoost применяют для задач вроде прогнозирования рейтинга игрока или его рыночной стоимости.
Так, SciSports отмечает, что их модель для оценки трансферной стоимости игрока обучена на данных 600 000 реальных трансферов и учитывает сотни факторов (статистика, возраст, позиция, уровень лиги, срок контракта и пр.). Вероятно, «под капотом» у них как раз алгоритм типа XGBoost, выдающий оценку стоимости с определенной точностью. Другой пример – прогноз успешности игрока при переходе в клуб: можно сформировать задачу бинарной классификации (успешно/неуспешно) на исторических трансферах и обучить бустинг-перевозчик (ensemble), чтобы он выделил комбинации факторов, ведущих к успеху.
Такие модели помогают снизить риски: если алгоритм показывает низкую вероятность адаптации игрока (например, слишком возрастной нападающий с падением физики, переходящий в более быструю лигу), клуб может воздержаться от трансфера. В целом, бустинговые модели ценятся за интерпретируемость: существуют методы (SHAP values и др.), позволяющие объяснить, какие именно признаки внесли вклад в решение модели.
Для спортивных руководителей это важно – им нужно понимать причины рекомендаций ИИ. Поэтому зачастую используются не самые «глубокие» нейросети, а композиции из нескольких понятных моделей. Например, в научной статье 2021 года предлагалась компромиссная модель на базе XGBoost и LASSO-регрессии для оценки ценности футболиста – подобные гибриды дают хорошую точность и при этом позволяют достать понятные коэффициенты признаков.
Графовые нейронные сети (GNN). Футбол прекрасно моделируется графами: игроки – это узлы (вершины), передачи/взаимодействия – ребра (связи), целая сеть пасов команды за матч образует граф. Поэтому графовые нейросети нашли применение в тактике и скаутинге. Например, исследовательская команда Google DeepMind разработала систему TacticAI, где GNN обучается на графе расстановки игроков и передач, чтобы подсказывать тренерам оптимальные корректировки тактики.
В скаутинге GNN помогают анализировать связи и сходства. Один из подходов – строить граф сходства игроков: узлы – игроки, а ребра (связи) связывают статистически схожих. Обучив GNN на таком графе, можно получать рекомендации по аналогам: например, если клуб ищет замену ушедшему правому защитнику, GNN найдет других защитников с аналогичным стилем (у которых узлы близко в графе). В отличие от простой кластеризации, GNN способна учитывать много сложных связей и обновлять «вектор представления» каждого игрока в процессе обучения, ориентируясь на соседей по графу.
Другой пример – социальные графы игроков: иногда смотрят, с кем игрок пересекался в командах, через одно рукопожатие и т.п., чтобы выявлять потенциальные нетривиальные знаки (скажем, игрок, ранее игравший в команде с высоким прессингом, легче адаптируется к подобной тактике, и это может быть отражено в графе). Еще одна задача – анализ игровых эпизодов: графы могут представлять взаимодействие игроков в конкретной фазе атаки, и GNN обучается выявлять удачные и неудачные шаблоны. Все эти применения пока больше находятся в сфере исследований, но постепенно проникают и в практику, особенно в топ-клубах с мощными R&D отделами (вроде «Манчестер Сити», «Пари Сен-Жермен», «Ливерпуль»).
Архитектура пайплайнов и инфраструктура данных. За красивыми витринами аналитических платформ стоит огромная работа по сбору, хранению и обработке данных. Современный клуб обычно выстраивает следующую архитектуру:
На уровне источников данных происходит интеграция различных потоков: это данные матчевой статистики (от Opta/StatsBomb – каждое действие в матче), трекинг (координаты игроков и мяча, 25 кадров в секунду), данные о тренировках (с GPS датчиков), медицинские данные, скаутские отчеты, данные с трансферного рынка (цены, контракты – напр. FIFA TMS) и даже данные соцсетей/новостей о характере и поведении игроков.
Далее все эти разнородные данные стекаются в единое хранилище (Data Warehouse). Часто используются облачные решения – Google BigQuery, AWS Redshift, Azure Synapse. Например, Английская FA начала с того, что централизовала все данные в BigQuery, упростив доступ и связь между ними. Это критически важно: без единого «озера данных» невозможно эффективно обучать модели, т.к. данные разрознены.
Поверх хранилища работает слой ETL/ELT (преобразование и загрузка данных). Он автоматизирует обновление данных: например, еженочно подгружаются свежие матчи, пересчитываются показатели за сезон, обновляются рейтинги. На этом этапе же происходит Feature Engineering – вычисление производных метрик. Например, сырые данные Opta о каждом касании мяча превращаются в агрегированные фичи: «количество прогрессивных передач за 90 минут», «% успешных отборов», «дистанция, продвинутая передачами вперед» и т.д. Опытные аналитики закладывают в этот слой свои ноу-хау, создавая «фичи 2.0» – метрики, лучше коррелирующие с успехом. Например, вместо простой дальности передач могут считать остроту передач с учетом xG, вместо количества обводок – коэффициент успешности обводок против среднего по лиге и т.д. Это улучшает качество последующих моделей.
Затем наступает черед собственно ML-моделей. Они могут обучаться офлайн (например, модель для предсказания успеха трансфера обучается на данных прошлых сезонов) или работать в режиме реального времени (например, модель, которая ранжирует игроков в коротком списке по заданным параметрам). Моделей, как правило, много, они решают разные задачи: классификаторы (подходит/не подходит стиль, будет/не будет играть за основу через год), регрессии (прогноз голов, оценки), кластеризация/редукция размерности (получить группы схожих игроков или уменьшить сотни показателей до нескольких главных компонент), рекомендательные системы (предложить игроков, похожих на данного). Все эти модели организованы в поток (pipeline): данные проходят через несколько моделей, фильтруются, результаты агрегируются. Например, пайплайн может выглядеть так: сперва фильтр по базовым критериям (возраст, позиция, доступны ли для трансфера) – затем модель прогнозирует потенциал каждого – затем берутся топ-10 по потенциалу и кластеризуются по стилю – затем для кластера нужного стиля считается прогноз адаптации к лиге – и в итоге выходят 2–3 фамилии, которые и передаются спортивному директору. Такие сложные многошаговые процессы ныне вполне реализуемы в коде и могут работать достаточно быстро.
Наконец, интерфейс и визуализация. Результаты анализа должны быть представлены в понятной форме для принятия решений. Здесь используются дашборды, отчеты и теперь уже чаты с ИИ. Дашборды – интерактивные панели (на базе Tableau, PowerBI или веб-разработки), где пользователь может сам выставить фильтры, сравнить игроков по параметрам, посмотреть графики тенденций. Очень популярны радары и тепловые карты – они наглядно показывают профиль игрока. Например, радиальная диаграмма по 8–10 основным навыкам (передачи, отборы, удары, дриблинг и т.д.) сразу дает визуальное представление, кто из двух игроков более атакующий и кто более оборонительный. Теплокарты показывают зоны активности на поле. Но в последнее время все больше внимания к текстовым выводам – многие руководители предпочитают короткое текстовое резюме, нежели изучать графики. Тут и выручают генеративные модели: они могут автоматически сгенерировать абзац вроде «Игрок A обладает высокой точностью длинных передач (85-й перцентиль), активно подключается в штрафную (xG 0,3 за 90мин), однако уступает по оборонительной работе (ниже среднего по отборам). Потенциально впишется в схему 4-3-3 на позиции опорника-разрушителя». Такой текст понятен и экономит время.
Итак, технологический стек AI-скаутинга включает хранилища больших данных, вычислительные облачные мощности, классические ML-алгоритмы (градиентный бустинг, нейросети, методы кластеризации), графовые модели и новейшие генеративные сети для NLP. Все это работает в комплексе, решая разные задачи. Например, BERT может проанализировать тональность отчета скаута (положительная/нейтральная/негативная), XGBoost – предсказать, сколько голов потенциально забьет форвард после перехода в команду (на основе миллионов случаев ), а GraphNet – найти структуру взаимодействий, делающую команду успешной.
Эмбеддинги и feature engineering позволяют представить игрока удобным для модели образом – например, как точку в пространстве из 100 признаков, которая затем используется для сравнения с другими точками. Без этих представлений глубокие модели не смогли бы эффективно учиться – сырой статистики слишком много и она разной природы. Потому лучшие результаты достигаются, когда эксперты по футболу и эксперты по данным вместе формируют правильные признаки и контролируют выводы моделей.
Важным компонентом является обеспечение надежности и актуальности системы. Технически это означает настройку мониторинга и обновления моделей. Например, данные футбола динамичны – стиль игры эволюционирует, поэтому метрики, бывшие важными 5 лет назад, могут потерять значимость. Инженеры должны регулярно проверять точность прогнозов моделей на новых данных и при необходимости переобучать их (обработка дрейфа данных). Также внедряются методы AutoMLи оптимизации гиперпараметров, чтобы модели оставались оптимальными.
Таким образом, современный AI-скаутинг – это синтез разнообразных технологий, объединенных в цельные системы поддержки решений. В них сочетаются как алгоритмы, принявшие участие в победах на Kaggle, так и уникальные разработки самих клубов. В погоне за талантами клубы фактически превращаются в IT-компании, конкурируя за лучших специалистов по данным и инвестируя в вычислительные мощности. Например, некоторые топ-клубы EPL развернули собственные дата-центры или арендуют облачные GPU для сложного моделирования. Это новая реальность футбола: битва идет не только на поле, но и на серверах и в коде.
Проблемы и риски: дрейф данных, смещения, оверфиттинг и дефицит информации
Несмотря на впечатляющие успехи, применение ИИ в скаутинге сопряжено с рядом проблем и ограничений – как технических, так и методологических.
Дрейф данных и изменение контекста. Модели, обученные на исторических данных, могут терять точность со временем. Футбол не статичен: появляются новые тактические тенденции, меняются правила (например, введение VAR, новое трактование офсайда, 5 замен вместо 3), что влияет на статистические паттерны. То, что было верным индикатором успеха 10 лет назад, сегодня может перестать работать.
Например, модель, предсказывавшая результативность форварда на основе количества ударов, может начать давать сбой, если в лиге вырос общий уровень реализации моментов (скажем, из-за улучшения полей или новых типов бутс). Это явление Data Drift требует постоянного мониторинга: нужно регулярно переобучать модели на свежих данных и проверять, не падает ли их качество.
Показательный кейс – пандемия COVID-19: сезоны 2020/21 прошли без зрителей, что существенно повлияло на динамику матчей (домашнее поле перестало давать такое преимущество, как раньше, игра шла более «тихо»). Модели, обученные на допандемийных данных, могли неверно калибровать, например, фактор домашнего поля. Клубам пришлось учитывать это и корректировать алгоритмы.
В более общем плане, каждый переход игрока в новый контекст – это своего рода дрейф: показатель, замечательный в одной команде, не гарантирует того же в другой. Аналитики пытаются компенсировать это, вводя поправочные коэффициенты для разных лиг и стилей. Например, известно, что 15 голов в Нидерландах примерно равны 7–8 голам в АПЛ по значимости – такие коэффициенты лиг закладываются в модели е. Но далеко не все факторы поддаются учету. Поэтому дрейф данных остается постоянным риском: модель нужно вовремя «ловить за хвост», пока она не начала систематически ошибаться.
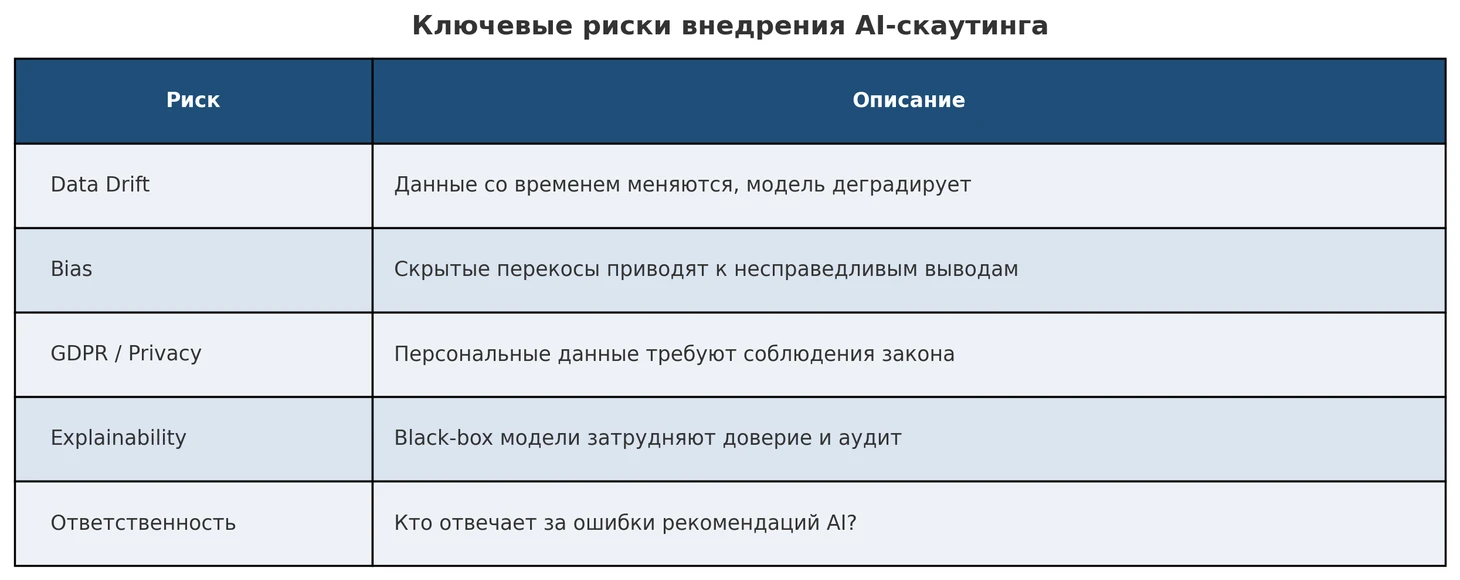
Смещения (bias) данных и алгоритмов. Данные, на которых обучаются модели, могут содержать скрытые смещения, которые приводят к необъективным результатам. В футболе примеров множество.
Географический bias: статистики по топ-лигам собираются куда более детально и точно, чем по экзотическим чемпионатам. В низших лигах может не вестись подсчет тонких метрик (скажем, интенсивности прессинга), из-за чего игроки оттуда неизбежно «висят в воздухе» в глазах модели. Алгоритм склонен недооценивать игрока из лиги, по которой мало данных, просто потому что не уверен. Это проблема малых выборок для «экзотических рынков» – талант из условной Малайзии может остаться незамеченным ИИ, потому что нет достаточного объема статистики, чтобы оценить его адекватно.
Культурный bias: данные могут не учитывать ментальные и адаптационные аспекты. Например, алгоритм может рекомендовать игрока из Южной Америки в английский клуб по цифрам, но не знает о языковом барьере и климате – а эти факторы могут сильно повлиять на эффективность.
Еще один пример – bias позиций: если модель училась на данных, где, к примеру, атакующие игроки всегда более ценны (дороже) чем защитники, она может занижать рейтинг перспективных защитников. Нужно специально вводить корректировки, чтобы ценные оборонительные качества были учтены.
Bias сборщиков данных: человеческий фактор при разметке событий тоже важен. Разные компании по-разному считают, что считать «ошибкой» или «успешным действием». Если клуб меняет поставщика данных, показатели игроков могут измениться из-за смены методики – модель может интерпретировать это как реальное изменение и сделать ложные выводы.
Overfitting и переусложненность моделей. Существует опасность, что модель «подгонят» под прошлые данные так, что она теряет способность к обобщению. В скаутинге это проявляется, когда алгоритм слишком фокусируется на уникальных сочетаниях признаков, успешных ранее, и пытается искать именно их, пропуская другие варианты.
Например, модель выявила, что успешные центральные защитники для АПЛ обычно имеют рост выше 185 см, выигранных воздушных дуэлей >70% и пас точность >85%. Это, возможно, верно для большинства топ-защитников прошлого, и модель начнет жестко фильтровать по этим критериям. В итоге она может отсеять талантливого защитника ростом 182 см – хотя его недостаток в росте компенсируется прыгучестью и выбором позиции. Скаут-человек мог бы это заметить, а переобученная модель – нет.
Чтобы бороться с переобучением, практикуют регуляризацию и контролируемое упрощение моделей. Часто полезно оставить в модели меньше признаков, но проверенных экспертно. Также помогает подход «человек в петле» – когда финальное решение принимает не алгоритм автоматически, а аналитик, просматривающий его предложения и способный включить здравый смысл.
Нехватка данных и качество данных. Не по всем важным аспектам игры доступны количественные данные. Например, нет общедоступной метрики «психологическая устойчивость» или «лидерские качества в раздевалке». Между тем, эти факторы порой определяют успешность перехода не меньше, чем техника.
Даже такие вещи как травматичность – данных мало и они закрытые (медкарты). Клубы пытаются косвенно учитывать: например, считать минутные нагрузки и восстановление, чтобы оценить риск травм, но 100% уверенности нет. К сожалению, ИИ не волшебник: без данных он не может учесть эти моменты. Это значит, что слепое доверие алгоритму рискованно, особенно если у игрока есть «красные флажки» вне поля (скандалы, нарушенная дисциплина и т.п.).
В истории были случаи, когда футболист идеально подходил по стилю и цифрам, но трансфер проваливался из-за проблем с характером или личной жизнью – ИИ здесь бессилен. Именно поэтому во многих клубах решение о трансфере принимается коллегиально: аналитики дают данные, скауты – мнение о личности, медики – о здоровье, тренеры – о соответствии тактике. Только совместив все точки зрения, клуб снижает риск ошибки.
Еще одна проблема с качеством данных – умышленные или случайные ошибки. Не все лиги могут похвастаться точностью Opta. Где-то статистика записывается вручную, есть промахи. Есть примеры, когда игрокам ошибочно приписывались голевые передачи или перепутаны имена в протоколе – если такие данные попадут в базу, модель воспримет их как истину.
Или другая ситуация: в малоизвестных лигах игроки часто приезжают на просмотр и уезжают, и базы данных могут задвоить профиль (чуть разное написание имени). Тогда статистика одного реального игрока распадается на два профиля, и алгоритм, видя по отдельности слабые данные, может его не заметить. Отсюда требование – качественная очистка данных: клубы тратят много времени на верификацию профилей, слияние дубликатов, исправление ошибок. Без этого ИИ-система будет не Garbage In – Garbage Out.
Этичность и ответственность ИИ. Еще один риск – чрезмерная автоматизация решений, способная привести к нежелательным последствиям. Например, если клуб решит полностью положиться на алгоритм при отборе молодых игроков в академию, есть вероятность, что будут упущены таланты «нестандартного профиля». ИИ может решить, что низкорослый 13-летний атакующий полузащитник не имеет шансов (по статистике обычно пробиваются более рослые на этой позиции) – и отсеет будущего Месси.
В этом плане необходимо помнить о человеческой интуиции и умении распознавать исключения. Оптимально, когда ИИ ассистирует, но не заменяет эксперта. Кроме того, если решения по игрокам принимаются полностью автоматически, возникает вопрос ответственности: кто виноват, если трансфер провален – скаут или «машина»? Юридически ИИ не субъект, отвечать будет спортивный директор. Но если он посчитался на безупречность алгоритма и прогорел, это ставит вопрос об адекватности такого использования ИИ. Европейские регуляторы уже обсуждают в рамках грядущего AI Act необходимость права на объяснение решений алгоритмов в значимых сферах.
В футболе ставки тоже высоки – трансферы на десятки миллионов, судьбы игроков. Поэтому клубы должны внедрять ИИ осознанно, сохраняя прозрачность и объяснимость. Желательно, чтобы модель могла пояснить, почему она рекомендует того или иного игрока (например, «у него высокие показатели xGChain и Key Passes, что ценно для вашей тактики»). Иначе возможно напряжение между ИИ-аналитиками и тренерским штабом: тренер может не доверять «черному ящику» и не ставить игрока, хотя «данные говорят, что он лучший вариант».
Правовые аспекты (GDPR и права игроков). Важнейшая проблема – соответствие использования данных о игроках нормам конфиденциальности и законодательства о защите данных. В ЕС действует GDPR, который признает персональными данными любые сведения, позволяющие идентифицировать человека – а значит, статистика игрока, его метрики физподготовки, медицинские данные – все это персональные данные.
Клуб, собирающий и обрабатывающий их, должен иметь законное основание. Обычно с действующими игроками проблем нет: трудовой контракт включает согласие на сбор данных в спортивных целях. Но при скаутинге клубы собирают данные на тысячи чужих игроков, с которыми нет договорных отношений. Вопрос – на каком основании? Многие полагаются на то, что спортивная статистика публична (протоколы матчей – открытые данные) и обработка ведется в легитимных интересах клуба (статья GDPR).
Однако четкой судебной практики по этому поводу еще нет. Показателен проект Project Red Card в Англии: группа из 400 профессиональных футболистов инициировала юридические претензии против компаний, торгующих данными их производительности (включая беттинговые компании и поставщиков данных). Они утверждают, что их личные данные использованы без их согласия и требуют компенсаций. Ситуация до конца не решена, но уже очевидно, что правовой ландшафт скаутинговых данных усложняется.
Клубам, возможно, придется получать согласие от игроков на глубокий анализ их данных – или анонимизировать их (но как анонимизировать статистику, привязанную к имени?). Пока регуляторы смотрят сквозь пальцы, признавая, что без данных спорт уже немыслим, но в любой момент могут возникнуть иски. Особенно рисково анализировать чувствительные данные (special category): например, данные медицины, генетики, этнического происхождения.
Такие вещи под GDPR требуют явного согласия. Если ИИ-модель учитывает, условно, расу или национальность игрока при прогнозе (а такие корреляции могут существовать – например, южноамериканцам может труднее адаптироваться к Европе статистически), то это прямое нарушение (автоматическое принятие решений с участием специальной категории данных). Клубы должны гарантировать, что их алгоритмы не используют запрещенные признаки для принятия решений, иначе возможны обвинения в дискриминации.
Прозрачность и объяснимость – важны не только с этической, но и с правовой точки зрения. GDPR содержит положение о праве субъекта данных на объяснение логики автоматизированного решения, которое существенно на него влияет. Представим, что алгоритм рекомендовал отчислить игрока из академии, и его контракт разорвали. Он может запросить: на каком основании? Клуб обязан предоставить рациональное объяснение (например, «ваши спортивные результаты в метриках X, Y не соответствовали требуемому уровню, и модель показала низкий потенциал роста»).
Если клуб скажет «так решила программа, и мы не знаем почему», это будет выглядеть с юридической стороны очень плохо. Поэтому отчетность AI-системы – необходимость. Некоторые клубы, предвидя это, ведут своего рода «журналы решений» – фиксируют, какие данные и как влияли на вывод модели. Это полезно и для внутреннего анализа точности, и на случай разборок.
Киберзащита и недобросовестное использование. Еще один риск – компрометация данных или алгоритмов. Футбольная аналитика стала объектом шпионажа: известен скандал 2015 года, когда скаут «Ливерпуля» незаконно получил доступ к закрытой базе «Манчестер Сити» и прочитал их трансферные планы. Сейчас, с развитием ИИ-скаутинга, утечка модели или базы данных может дать конкурентам большой инсайд. Поэтому клубы вынуждены инвестировать и в кибербезопасность, шифрование данных, ограничение доступа. Также важно избегать конфликтов интересов: некоторые аналитические фирмы обслуживают сразу несколько клубов – нужно быть уверенным, что твои данные не попадут к прямому конкуренту.
Наконец, чисто спортивный риск: унификация подходов. Если все клубы будут пользоваться одинаковыми моделями и данными, то все придут к одним и тем же целям. Уже сейчас топ-таланты вроде хафбека с идеальными метриками видны всем – начинается аукцион, цена растет. Рынок становится более эффективным, и найти undervalued gem все труднее.
Налицо парадокс: ИИ приносит на первых порах большое преимущество тем, кто внедрил раньше, но по мере распространения технологии преимущество сглаживается. В будущем, если все будут полагаться на алгоритмы, возможно, стоимость игроков будет почти идеально отражать их вклад (как на бирже), и тогда заработать на разнице будет крайне сложно. Это заставляет задуматься: не приводит ли дата-скаутинг к тому, что богатые клубы просто еще быстрее скупят всех талантов, а у аутсайдеров не останется даже временного фору? Пока такого не произошло – небольшие клубы вроде «Брентфорда» и «Брайтона» доказывают, что грамотная аналитика позволяет обыгрывать миллиардеров. Но с каждым годом это окно возможности сужается.
Подытоживая, проблемы AI-скаутинга требуют не меньше внимания, чем его преимущества. Необходимо:
следить за релевантностью моделей (бороться с дрейфом, переобучением),
устранять и осознавать потенциальные смещения (особенно в отношении игроков из менее представленных групп или лиг),
сохранять человеческий контроль и обеспечивать объяснимость решений,
соблюдать юридические нормы и права игроков на приватность их данных,
защищать данные от утечек и злоупотреблений.
Только при ответственном подходе ИИ-скаутинг будет инструментом помощи, а не источником новых проблем.
Право и этика: GDPR, права данных игроков, объяснимость и ответственность
Внедрение ИИ в спортивную селекцию поднимает серьезные правовые и этические вопросы. Рассмотрим основные из них – от конфиденциальности данных игроков до ответственности за решения алгоритмов.
Конфиденциальность и GDPR. Как уже упоминалось, в Европе сбор и обработка персональных данных (к которым относится и спортивная статистика, если она привязана к имени игрока) регулируется Общим регламентом по защите данных (GDPR). Клубы обязаны иметь законное основание для обработки данных игроков. С собственными футболистами проще – обычно в контракт включены пункты о согласии на сбор данных в тренировочных и медико-спортивных целях. Но когда речь о скаутинге внешних игроков, ситуация сложнее.
Наблюдение за чужим игроком, сбор его статистики, ведение на него досье – формально обработка персональных данных без прямого согласия субъекта. Клубы полагаются на положение о «легитимном интересе» (Legitimate Interest), утверждая, что селекционная деятельность – естественная часть бизнеса футбольного клуба, и она не нарушает прав игрока, ведь используется преимущественно публичная информация (матчи открыты для публики). Однако это поле пока серое.
Недаром возник Project Red Card – уникальный прецедент, когда сотни игроков объединились, чтобы отстоять контроль над своими данными. Они потребовали компенсаций от компаний, торговавших детальными техническими данными их выступлений без разрешения, заявляя, что у этих фирм не было ни согласия игроков, ни иной законной основы. Ситуация находится в процессе разрешения: возможно, дело дойдет до суда, который установит, считать ли профессиональную статистику «общественным достоянием» или персональным активом игрока.
В зависимости от исхода, футбольным клубам и лигам, возможно, придется пересматривать договоры и получать дополнительные согласия. Уже сейчас многие клубы включают в контракты с игроками обширные параграфы, покрывающие сбор данных (включая медицину, трекинг и т.д.) – чтобы обезопаситься от претензий в будущем.
Специальные категории данных. GDPR определяет особую категорию чувствительных данных, требующих явного согласия или иных строгих оснований: это данные о здоровье, биометрия, этническое происхождение и т.п. В футболе пример – медицинские данные игроков (тесты, история травм). Их очень ценно анализировать (например, для прогнозирования травматичности трансфера), но тут нельзя просто так обмениваться информацией. Обычно медданные строго конфиденциальны внутри клуба.
Перед трансфером обмен медицинской информацией происходит с согласия игрока (через медосмотр). Аналогично, биометрия с датчиков (пульс, ускорения) – спорно, можно ли использовать эти данные при скаутинге без согласия игрока. Теоретически, если в трансляцию матча вшита телеметрия (как, например, в NFL публикуют данные NextGen), то эти числа уже публичны. Но если клуб-соперник установил свои камеры и сам отследил биометрию чужого игрока – это потенциально нарушение. Пока прецедентов мало, однако нужно иметь это в виду.
Права игроков на свои данные. GDPR дает человеку ряд прав: право на информацию, какие данные собраны; право на исправление неточностей; право на удаление (быть забытым) и т.д. Представим, игрок может обратиться в клуб-конкурент: «Я знаю, что вы собирали на меня досье, предоставьте мне копию».
Формально, если клуб выступает контролером данных, он обязан ответить. Но клуб может сказать: мы не контролер, мы получили их от третьей стороны. Или сослаться на исключение для исключительно личных или домашних целей (маловероятно применимо к бизнес-деятельности). Этот правовой казус еще предстоит разрешить. Вероятно, будет достигнут отраслевой консенсус или регулирование, которое даст спортивным организациям особые условия.
Уже обсуждаются идеи, что игроки могли бы лицензировать свои данные (например, через профсоюзы), чтобы клубы могли их использовать легально, а игроки – получать долю от коммерческого использования (например, букмекерами).
Explainability (объяснимость) и non-discrimination. С этической точки зрения, ключевой принцип – отсутствие дискриминации и прозрачность алгоритмов. Алгоритмы не должны принимать решений, ущемляющих людей по запрещенным признакам (раса, религия, национальность и т.д.).
В футболе, как ни странно, подобные риски существуют. Например, если модель увидит, что футболисты из определенной страны статистически не оправдывают ожиданий в другой лиге, ее рекомендации могут фактически исключать игроков по национальному признаку – это скользкая дорожка. Клубу следует убедиться, что модель опирается на спортивные факторы, а не косвенно находит «ярлыки».
В идеале, в алгоритме должны быть защитные механизмы от такого (например, явное исключение поля «национальность» из признаков и проверка корреляций). Что касается объяснимости, то футбольные клубы пока не обязаны публично объяснять свои кадровые решения. Но внутри организации это необходимо для доверия: тренерский штаб должен понимать логику аналитики.
В некоторых клубах аналитики составляют «отчет об обосновании» для каждого рекомендованного трансфера – там в текстовой форме расписывается, почему этот игрок подходит, с указанием ключевых метрик (в сравнении со средними, с лучшими в лиге и т.д.). Это своего рода перевод алгоритмических выводов на язык, понятный тренерам и руководству. Такой подход – элемент этики в широком смысле: он обеспечивает, что решения принимаются сознательно, а не слепо по подсказке «черного ящика».
Ответственность и человеческий контроль.Международные принципы этики ИИ (IEEE, EU guidelines) гласят, что финальная ответственность должна оставаться за человеком, а ИИ – лишь вспомогательный инструмент. В футбольном клубе это реализуется тем, что спортивный директор или тренер имеют право вето на рекомендации ИИ. Нередко приводят пример: если данные и скауты расходятся во мнении, решение принимает комитет во главе с директором, который взвешивает оба мнения.
Если затем трансфер окажется неудачным, виновник понятен – руководство, которое решило так поступить (либо довериться данным вопреки мнению скаутов, либо наоборот). Такая структура ответственности стимулирует и ИИ-аналитиков лучше объяснять свои рекомендации, и скаутов – быть более объективными.
Юридическая ответственность за ошибки ИИ – пока не отдельно прописана в спортивном праве. Если клуб понес убытки от трансфера, потому что модель оказалась некорректной – это риск клуба, а не разработчика модели. Большинство AI-решений поставляются без гарантий: провайдеры дают инструмент «как есть», а пользование им – зона риска клуба. Поэтому многие топ-клубы предпочитают строить модели инхаус, чтобы компетенции и понимание оставались внутри. Это тоже часть этики доверия: когда решение принимает своя база данных, клуб больше ей доверяет и принимает ответственность, чем если использовать неясный внешний сервис.
Неэтичное использование ИИ. Стоит упомянуть и потенциально неэтичные сценарии: например, использование ИИ для манипуляций (представим, агенты могли бы генерировать фейковые данные или видео при помощи deepfake, чтобы «продать» игрока – пока это фантастика, но технологии двигаются). Или сбор личных данных игрока вне поля (посты в соцсетях, лайки и т.п.) – клубы, возможно, уже мониторят поведение кандидатов в соцсетях с помощью ИИ, чтобы оценить психологический профиль.
Это скользкая тема – граница между публичным имиджем и частной жизнью. Этически клуб не должен вторгаться в личное пространство игрока, но если игрок публично выкладывает в Instagram ночные вечеринки – эти данные могут повлиять на решение о трансфере. Тут скорее вопрос репутации: клубы не афишируют такие вещи, но, вероятно, учитывают.
Справедливость к игрокам. Еще один этический момент – честность по отношению к игрокам. Если ИИ-система ошиблась (а это неизбежно иногда), кто-то из игроков может быть недооценен или упущен, а кто-то переоценен. В первом случае – упущенный талант страдает (не получил шанс из-за машины), во втором – клуб страдает, потратив деньги. Это неизбежно, но важно, чтобы ИИ не заменял прямое общение. Многие специалисты отмечают: нельзя забывать про «тест глазом» и личные встречи.
Бывали ситуации, когда по цифрам игрок идеален, а при личном общении тренер понимал – не подойдет ментально. Обратное тоже: цифры средние, но у парня горят глаза и есть харизма лидера – ему дают шанс и не жалеют. Этический скаутинг сохраняет баланс между данными и уважением к индивидуальности игрока.
Право интеллектуальной собственности на данные. В завершение отметим интересный юридический аспект: кому принадлежат данные, сгенерированные ИИ? Например, если модель генерирует отчет о игроке, защищен ли он авторским правом? Возможно, нет, если считается чисто автоматическим. Но если аналитик доводит его до ума, это уже может считаться аналитическим трудом, который клуб захочет защитить от разглашения. Пока это тонкости, не сильно регулируемые. На практике все решается соглашениями о конфиденциальности: сотрудники аналитического отдела и контрагенты подписывают NDA, запрещающие им делиться внутренней информацией о моделях и находках.
Подводя итог, можно сказать: законодательство пока не совсем поспевает за быстрым внедрением ИИ в спорт, однако основные принципы понятны. Клубам важно:
Соблюдать приватность игроков, не злоупотреблять данными, которых они не должны иметь.
Получать согласия, где это необходимо, и информировать игроков (например, в некоторых клубах игрокам объясняют, какие данные о них собирают и зачем – это повышает доверие).
Предотвращать дискриминацию, проверяя модели на наличие скрытых предубеждений.
Обеспечивать объяснимость решений внутри организации, а в идеале – быть готовыми объяснить их и вовне, если потребуется.
Оставлять за человеком последнее слово и тем самым нести ответственность за решения, а не перекладывать ее на алгоритм.
Этика ИИ-скаутинга во многом сводится к одному: использовать данные во благо спорта и игроков, а не во вред. Если ИИ помогает найти молодому игроку идеальный клуб, где он раскроется – это благо. Если ИИ приводит к тому, что талантливый парень остается без контракта из-за какой-то аномалии в цифрах – это упущение, которое нужно стараться минимизировать. Баланс интересов клубов, игроков и болельщиков должен быть сохранен, и правовое регулирование постепенно выработается, чтобы этот баланс поддержать.
Выводы и перспективы (кто дошел до финала, тот герой)
ИИ уже меняет роль спортивного директора и весь процесс принятия решений в футболе, и эта трансформация будет углубляться. Традиционный спортивный директор полагался на сеть скаутов и свое чутье; новый спортивный директор все больше напоминает руководителя аналитической компании. Он должен разбираться в метриках, понимать отчеты от data-отдела, уметь задать правильные вопросы ИИ-системе. Его решения теперь подкреплены тоннами данных и прогнозов. Например, если раньше прицел трансфера мог определяться фразой «понравился напор парня», то теперь – «у парня 92% успешных действий под давлением, это топ-показатель».
Роль спортивного директора эволюционирует от «искателя» к «интегратору» – интегратору информации от скаутов, аналитиков, тренеров и агентов. Это требует новых навыков: понимания основ статистики, умения общаться с техническими специалистами, критического мышления по отношению к выводам алгоритмов. Можно ожидать, что в штабах клубов появятся и новые позиции – например, AI-этический консультант (следить, чтобы модели не вели к дискриминации или нарушению прав) или интерпретатор данных (переводить сложные аналитические инсайты на язык футбола).
Для самих скаутов ИИ – не враг, а скорее усилитель. Освободившись от рутинной работы (просмотра десятков посредственных матчей в поисках одного яркого игрока), скауты могут сконцентрироваться на более тонких вещах: оценке характера игрока, его соответствия культуре клуба, «химии» с будущими партнерами. ИИ же возьмет на себя предварительный скрининг и подсказки, кого стоит мониторить.
В этом плане профессия скаута не исчезнет, а изменится – станут востребованы скауты, способные дружить с данными. Уже сейчас лучшие селекционеры учатся читать аналитические отчеты и использовать их как еще один инструмент наряду с собственными наблюдениями.
Конкурентоспособность клубов в эпоху AI будет зависеть от способности быстро внедрять и адаптировать новые технологии. Первопроходцы вроде «Брентфорда» получили преимущество и смогли пробиться наверх, во многом благодаря тому, что опередили более богатых соперников по части интеллектуального подхода. Но топ-клубы не дремлют: уже сейчас практически во всех командах АПЛ есть департамент анализа данных, а такие гранды, как «Манчестер Сити» или «Бавария», вкладывают миллионы в собственные информационные платформы.
Разрыв между продвинутыми и отстающими клубами может увеличиться: те, кто не инвестирует в AI, рискуют превратиться в «доноров» – их сильных игроков будут дешево забирать более умные конкуренты, умеющие распознать талант раньше. С другой стороны, есть мнение, что распространение аналитики выровняет правила игры: когда все используют похожие методы, найти скрытые преимущества становится сложнее, и все возвращаются к конкуренции ресурсами и человеческим факторам.
Однако на ближайшую перспективу (5–10 лет) у прогрессоров есть окно возможностей. В среднесрочной перспективе мы, вероятно, увидим еще больше кейсов, похожих на «Брентфорд»: небольшие клубы будут выбиваться в еврокубки, удивляя всех, а потом окажется, что за их успехом стояла мощная аналитическая программа.
Стратегическое влияние ИИ на футбол проявится и на трансферном рынке, и в самой игре. Клубы станут осторожнее тратить большие суммы на «именитых, но неподходящих» игроков – данные снизят число импульсивных приобретений ради статуса. Возможно, цены на игроков станут более обоснованными: когда у всех есть примерно одинаковая информация о перспективах игрока, рынок становится эффективнее (мы уже наблюдаем, как молодые игроки с впечатляющими метриками, даже без большого имени, оцениваются очень высоко – благодаря тому, что клубы видят их «скрытый» потенциал цифрами).
С другой стороны, элемент сюрприза и удачи все равно останется. Футбол – слишком сложная и человеческая игра, чтобы ее можно было просчитать на 100%. ИИ не гарантирует побед, он лишь повышает шансы на успех при грамотном использовании. Спортивный директор будущего – это оркестратор, который должен свести воедино и холодные рекомендации алгоритмов, и горячую интуицию тренерского штаба, и финансовые ограничения, и часто иррациональные факторы (давление фанатов, медийность).
Интересно, что границы между ролями могут смещаться: спортивные директора, освоившие ИИ, начнут участвовать и в тактическом планировании (раз понимают данные – могут советовать тренеру), а тренеры, получившие мощные аналитические инструменты, будут влиять на селекцию (например, прося аналитиков найти игрока под их специфические требования). Все больше решений будет приниматься коллективно, на основе единой информационной картины, которую дает клубу его центр данных.
На горизонте видны и новые перспективные направления применения ИИ:
Реал-тайм анализ матчей с генеративными рекомендациями – например, ИИ во время игры подсказывает тренеру: «замени левого защитника, у него падает выносливость, и через эту зону может пройти атака» (такие разработки ведутся, и хоть тренер сам принимает решение, ему дают дополнительную подсказку).
Персонализация тренировок – на основе данных ИИ будет составлять индивидуальные программы для игроков, учитывая их слабые места и даже психологическое состояние .
Прогнозирование травм с помощью AI – анализ больших данных нагрузок и медицинских показателей, чтобы заранее предупреждать тренера о риске травмы и давать отдых игроку .
Виртуальные спарринги и симуляции – генеративные модели, обученные на стиле разных команд, могут симулировать матч (например, как бы сыграла наша команда против «Ман Сити»). Это поможет оценивать, впишется ли потенциальный новичок в команду: прогнать симуляцию с ним в составе. Это пока теория, но при достаточных данных и мощности ИИ может стать реальностью.
Новые метрики влияния – возможно, появятся еще более тонкие показатели (например, «вклад в прессинг командный индекс» или «индекс креативности»), рассчитываемые нейросетями с учетом множества факторов, которые станут стандартом оценки вместо примитивных голов+передач.
Все это кардинально меняет подход к управлению клубом. Роль спортивного директора становится ближе к роли CEO tech-компании, где решения принимаются на базе данных, а не только на интуиции. Но это не умаляет человеческого фактора. Напротив, востребованы лидеры, способные сочетать технологичность и человеческое понимание игры.
Футбол – это не только цифры, но и эмоции, психология, командная химия. ИИ пока не может измерить дух команды или сердце игрока. Возможно, в будущем появятся попытки оценивать и это (например, алгоритмы анализа мимики, речи игроков для оценки психотипа). Но окончательно «оцифровать» футбол вряд ли удастся – и это к лучшему, ведь непредсказуемость и магия игры останутся.
Что однозначно изменится – это скорость и эффективность процессов. Трансферные решения, на которые раньше уходили месяцы дебатов, теперь могут приниматься за дни, потому что все необходимые данные доступны сразу. Спортдиры отмечают, что AI-инструменты экономят им до 70% времени на анализ кандидатов.
Это позволяет уделять больше внимания стратегии развития клуба – планированию на несколько лет вперед, работе с академией, налаживанию связей и т.д. ИИ может даже помочь ответить на вопрос: как выстроить конкурентоспособную команду с ограниченным бюджетом? – путем моделирования разных сценариев комплектования состава.
В долгосрочной перспективе ИИ в скаутинге может повлиять и на общий баланс сил в футболе. Если топ-клубы получат подавляющее преимущество в аналитике, разрыв с остальными увеличится. Но возможно и обратное: универсальная доступность данных (многие метрики становятся открытыми, а модели – opensource) приведет к тому, что «бриллианты» больше не будут зарыты во втором дивизионе – их все будут сразу видеть.
Тогда конкуренция сместится на другую плоскость: кто предложит игроку лучший проект, условия, тренировочный план. То есть «мягкие» факторы выйдут на первый план, когда «информационное равенство» будет достигнуто. Мы к этому идем: уже сейчас болельщики в Twitter могут с помощью публичных данных (Opta, Transfermarkt, WyScout – аналитические сервисы) находить и предлагать клубам интересных игроков – такое было с Митома в «Брайтоне», например, когда профильные блогеры указывали на него, опираясь на статистику. Это говорит о демократизации данных.
Тем не менее, умение правильно этими данными пользоваться – удел профессионалов. Поэтому роль людей никуда не исчезнет. Скорее, изменится их квалификация. Футбольный менеджмент станет более научным, а успешные спортивные директоры будущего будут походить на гибрид аналитика, стратега и психолога. Они будут принимать решения, глядя не только на таблицу чемпионата, но и на дашборды с показателями эффективности академии, на отчеты AI о потенциальных целях, на финансовые модели окупаемости трансферов.
В заключение, можно констатировать: ИИ-скаутинг – уже не фантастика, а повседневность в современном футболе. Он прошел путь от вспомогательного инструмента до одного из центральных звеньев в цепи управления клубом. Правильное внедрение ИИ способно дать существенное преимущество, но требует инвестиций, культуры данных и соблюдения этических норм. Те клубы, которые освоят эту науку, смогут обгонять конкурентов, даже обладающих большими финансовыми ресурсами. Однако в конечном счете футбол остается игрой людей.
Данные дополняют, а не заменяют человеческий фактор. ИИ меняет роль спортивного директора, но не отменяет ее – просто наполняет новым содержанием. Можно с уверенностью сказать, что в ближайшие годы мы увидим еще немало сенсаций, сотворенных благодаря удачным аналитическим находкам, и так же увидим провалы, когда слепая вера в алгоритм сыграла злую шутку. Футбол тем и прекрасен, что не укладывается до конца ни в какие формулы. Но тот, кто сумеет максимально полно и грамотно использовать доступную информацию, несомненно будет ближе к успеху. А генеративный ИИ и другие AI-технологии станут верными помощниками тех, кто готов их использовать ответственно и творчески – превращая сырые данные в победы на поле.
Коллеги, Вы большие молодцы, если дочитали до конца! Попрошу Вас оценить мою работу путем максимального распространения!
* Деятельность компании Meta запрещена в РФ

























Такой оцифрованный человек не будет развиваться, голос не будет меняться от возраста, по сути это будет слепок на какой-то момент времени, не более.
Все нынешние «ии» это хороший инструмент, позволяющий избавиться от доброй доли рутины в работе, и его стоит рассматривать именно с этой стороны
Ну и в заголовок бы вынес про нейронки и мо, а не только про gen. Про генеративный ии всё же в тексте малая часть