
Если вы первый раз в этом блоге, то предлагаю прочитать предыдущие статьи (первая и вторая), иначе таблицы ниже могут показаться списками из случайных игроков.
Добавляем стилистические особенности лиг
После последней статьи у автора были слишком амбициозные планы. В частности, хотелось научиться распределять Pass EPV награду между пасующим и принимающим передачу. К сожалению, не успел это сделать. Единственное, что добавил (благо, это было не трудно), стилистические особенности лиг.
В прошлый раз мы добавили в качестве признаков рейтинги команд и лиг. Таким образом мы учли то, что у игрока могут просесть метрики, если он перейдет из сильной лиги в слабую. Однако значительное изменение в уровне команды и в уровне сопротивления в чемпионате не единственный фактор, который влияет на перформанс игрока.
Давайте порассуждаем, что такое рейтинг команды. Чем команда чаще выигрывает (с поправкой на силу соперника), тем рейтинг выше. Но выигрывать можно по-разному. Можно выигрывать 4:3, а можно 1:0. Это важный момент, так как PRR характеризует действия футболиста с мячом. Соответственно, игроку в атакующей команде играть «выгоднее». В прошлый раз мы учитывали такой момент, считая признаки, вроде какую долю PRR от всей команды создает игрок. Однако имеет смысл учесть общую ситуацию по лиге.
Таким образом, были посчитаны признаки, вроде: «средний PRR в лиге», «средний PRR в лиге по конкретной позиции» и т.д. Такие признаки помогут нам учесть стилистические особенности чемпионатов, что увеличит точность модели, так она будет учитывать такой немаловажный фактор, как адаптацию футболиста в новой лиге.
О названии блога
Обычно задача машинного обучения решается так. Рассмотрим на примере xG.
Есть данные, которые представлены в виде, например, таблицы. Каждая строчка представляет собой пример данных (в нашем случае удар). Каждый столбик как-то описывает этот пример (расстояние до ворот, удар был нанесен головой или ногой и другие). Один из столбиков особенный и представляет из себя целевую переменную (был гол или нет, 0 или 1).
Решение задачи происходит в два этапа.
Обучение (fit). На этом этапе мы обучаем модель подгоняться (отсюда и fit) под данные. На примерах по признакам модель учится отличать таргеты от друг друга.
Прогноз (predict). Уже обученную модель мы применяем на новых данных (модель не знает значения целевой переменной), прогнозируя таргет.
Почему (а точнее при каких обстоятельствах) все это безобразие работает? Тут принцип такой: данные на этапе обучения должны быть похожи на данные на этапе прогноза. Если вы обучили xG на данных АПЛ, а применили на данных по матчу между командами пятого «А» и шестого «Б», то у вас получится дичь. По понятным причинам.
Почему вообще происходят трансферы
В прошлый раз мы обозначили проблему, которую описали парой фраз «Модель строится на реальных данных (трансферах). Это значит, что потенциальный трансфер в наш клуб должен быть более-менее реалистичным. Прогноз PRR для Кевина де Брюйне в чемпионате Венесуэлы скорее всего будет неадекватным.»
На практике все оказалось гораздо веселее. Обсудим эту проблему подробнее. Мы создаем инструмент для селекционера, то есть подразумевается, что игрок сменит клуб или даже лигу. Мы строим модель на реальных данных, на реальных трансферах. Это значит, что модель будет учиться на примерах, вроде «игрок перешел из лиги с таким-то рейтингом в лигу с таким-то рейтингом, из команды с таким-то рейтингом в команду с таким-то рейтингом и показал такой-то результат».
Здесь и кроется проблема. Наш эксперимент «не честный». Игроки переходят из клуба в клуб неслучайно. Рассмотрим три ситуации:
Игрок перешел в более сильный клуб. Если футболист перешел из слабого клуба в более сильный, то скорее всего новый клуб считает, что игрок хороший. А поскольку мы считаем, что в руководстве большинства клубов не дурачки работают, то у нас есть все основания полагать, что игрок действительно хорош (или обладает потенциалом, чтобы стать таким игроком).
Игрок перешел в более слабый клуб. Если футболист перешел из сильного клуба в более слабый, то по логике из предыдущего пункта у нас есть повод полагать, что игрок стал деградировать.
Игрок остался в старой команде. Если футболист никуда не перешел, то будто бы все в норме. Игрок не стал значительно сильнее/слабее. Но даже в таком случае могут возникать ситуации, когда игрок стал играть значительно лучше/хуже, но в новый клуб не переходит.
Как работает наша модель
Обучаем модель мы на реальных трансферах. Однако на этапе прогноза мы заполняем признаки связанные с новым клубом значениями соответствующими «нашему» клубу. Например, мы хотим предсказать значения PRR в новом сезоне для игрока в случае его перехода в Манчестер Сити. Мы заполним признаки «рейтинг нового клуба», «средний рейтинг новой лиги» значениями соответствующими Манчестеру Сити и АПЛ. В этом и проблема, мы фактически сообщаем модели, что игрок скорее всего очень хороший.
Presence-only data problem
Подобная проблема известна как «presence-only data» или «learning from positive and unlabeled data».
Классический пример: хочется построить модель, которая предсказывает, водится ли суслик в определенной местности или нет. Давайте соберем данные: отправим экспедиции в разные места. Если суслика нашли, то значит он там водится, а если не нашли, то это еще не значит, что его там нет.
Таким образом, если мы будем обучать модель на результатах экспедиций, то мы будем предсказывать вероятность найти суслика, а не вероятность того, что он там водится.
У нас похожая ситуация. Трансферы не случайны, а, значит, прогноз PRR в случае перехода игрока в значительно более сильный клуб будет оптимистичным.

Корректируем прогнозы
Нам как-то нужно скорректировать «оптимистичность» прогнозов относительно переходов из слабых лиг в сильные и «пессимистичность» из сильных в слабые.
Также нужно учесть тот факт, что есть вероятность, что игрок завершит карьеру или по каким-то другим причинам не сыграет в следующем сезоне значительное количество времени. Если пренебречь этим, то прогноз окажется немного оптимистичным, так как модель обучалась на игроках, по которым были данные в следующем году. В прошлый раз мы построили вспомогательную модель, которая предсказывала, сыграет ли игрок в следующем году хотя бы 100 чистых минут.
Итак, у нас есть разница в рейтингах лиг и вероятность, что игрок «исчезнет» из данных (обозначим за PL). Также обозначим за ratings_difference = (Рейтинг(новой лиги) - Peйтинг(старой лиги)) / 1500, здесь 1500 - это средний рейтинг всех клубов. В итоге было решено добавить следующую корректировку прогноза PRR:
PRR* = PRR * 0.8 ^ (ratings_difference + PL).
Суть формулы такая:
если высока вероятность, что игрок не сыграет 100 чистых минут в следующем сезоне, то уменьшаем предсказанное значение;
если игрок переходит в более сильную лигу, то уменьшаем предсказанное значение;
если игрок переходит в более слабую лигу, то увеличиваем предсказанное значение.
Результаты
Ниже представлены таблицы с игроками с наибольшими прогнозами PRR* для Ливерпуля, Милана, Реала, Фламенго и Бока Хуниорс. Слева просто 25 игроков, справа в возрасте до 25 лет.
Шорт-листы для Ливерпуля:
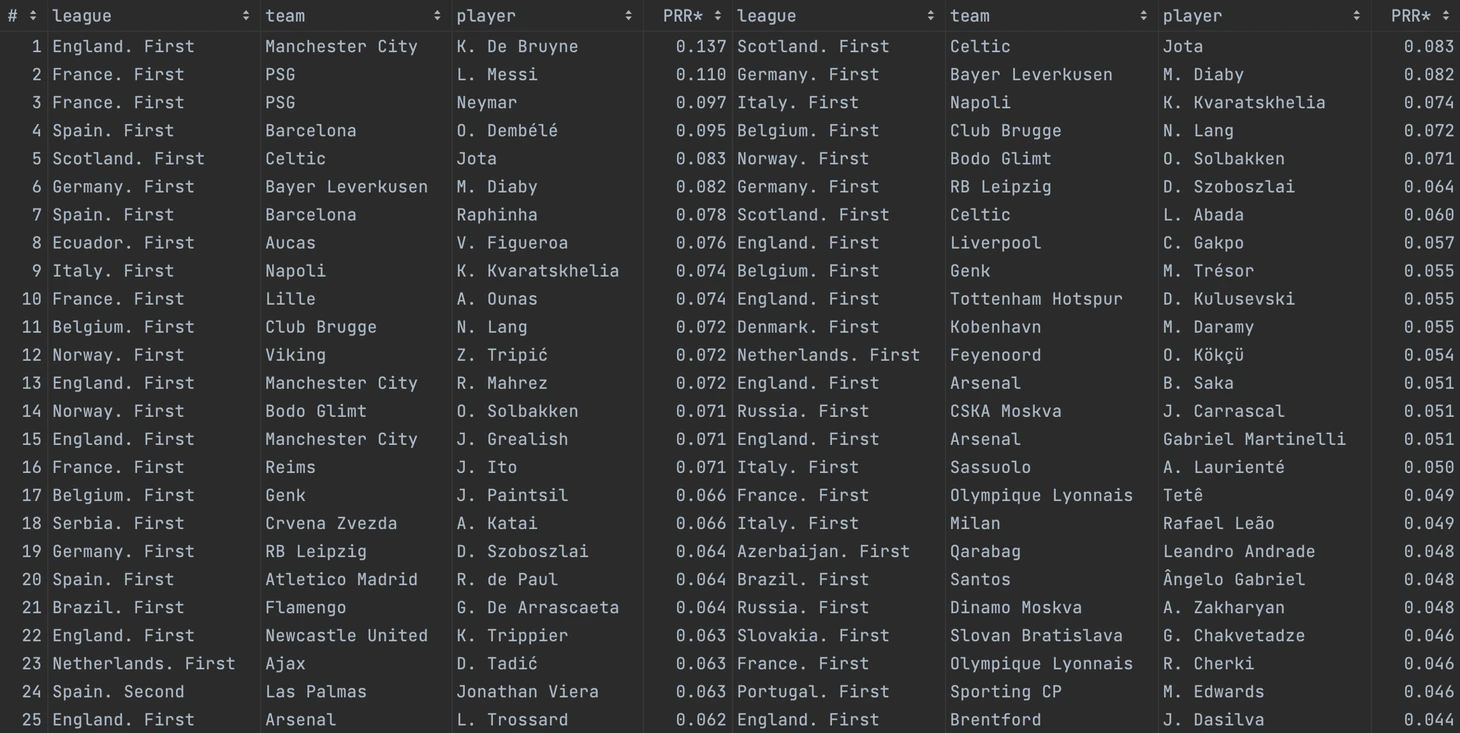
Шорт-листы для Милана:
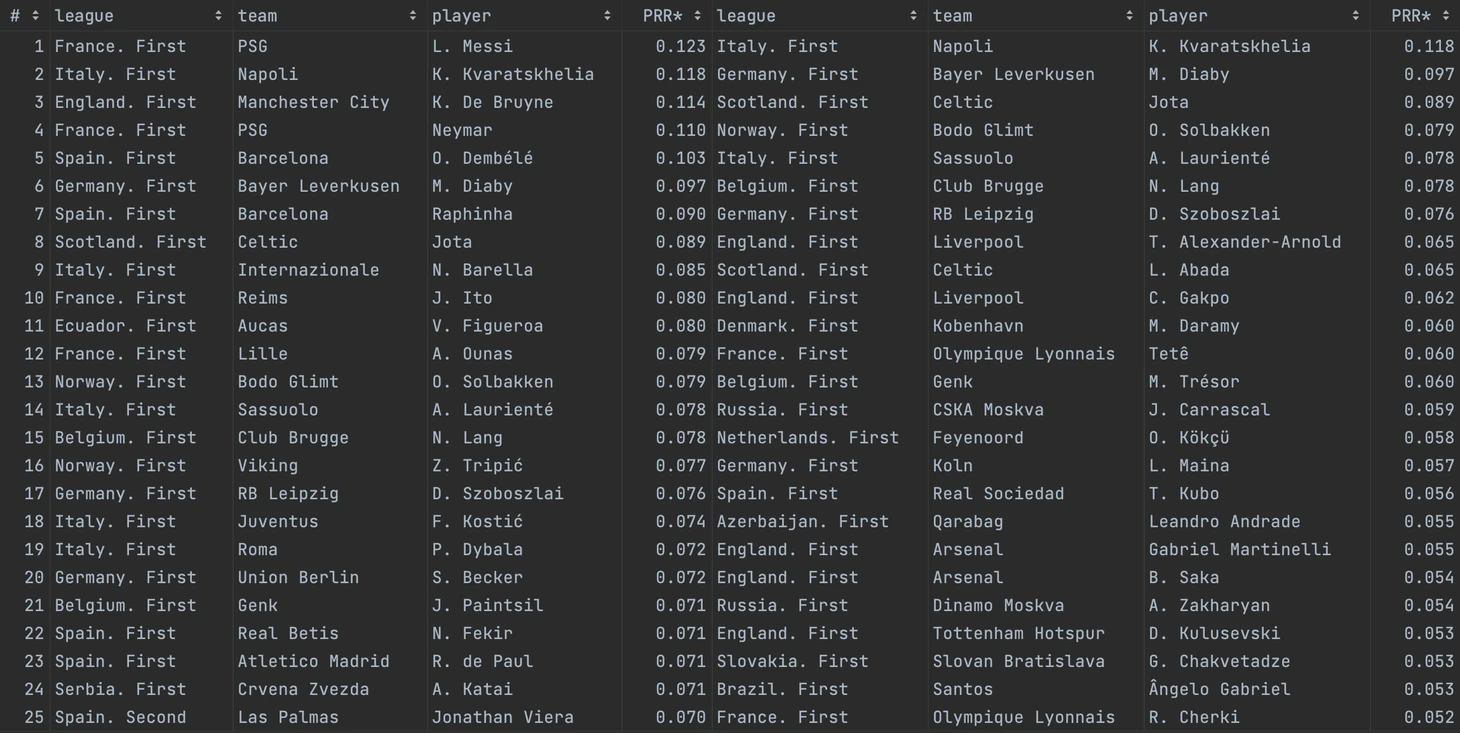
Шорт-листы для Реала:
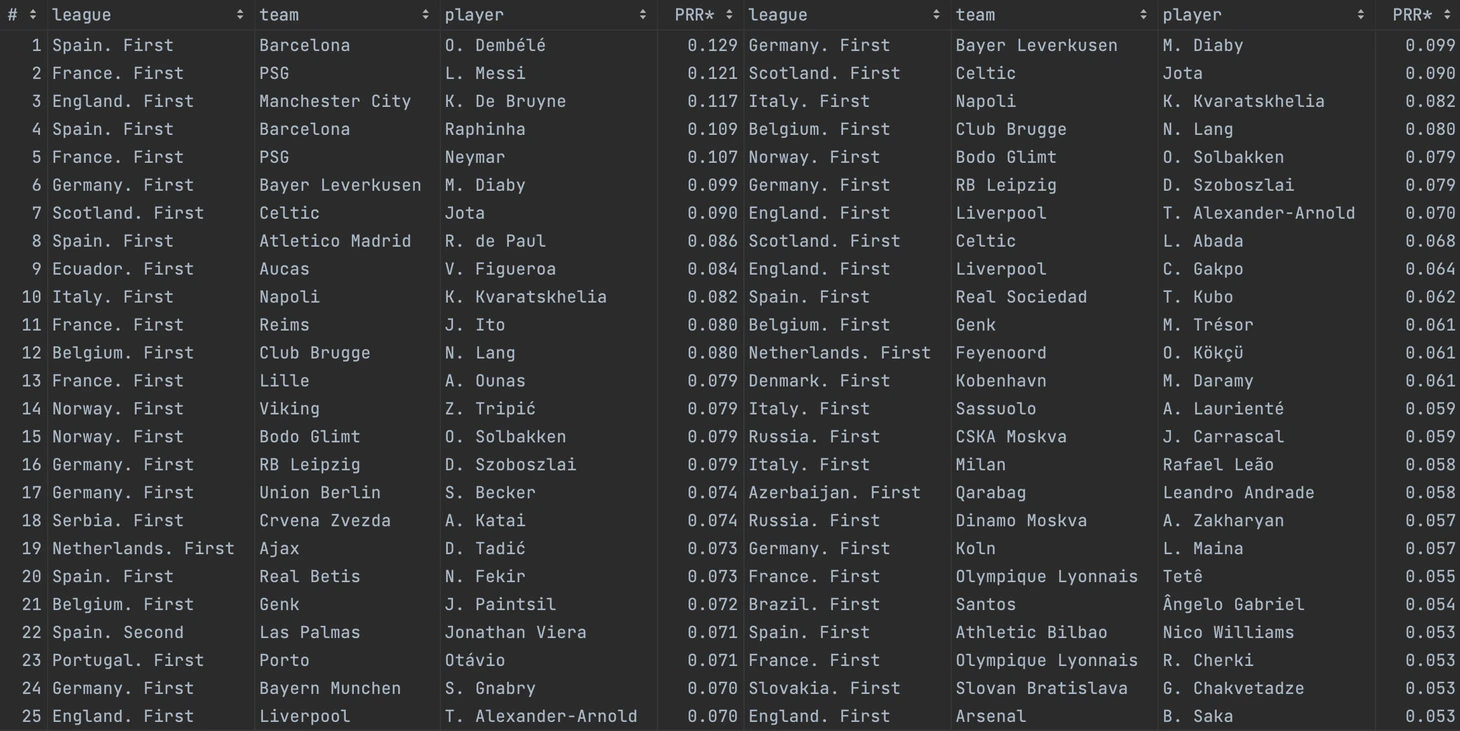
Шорт-листы для Фламенго:
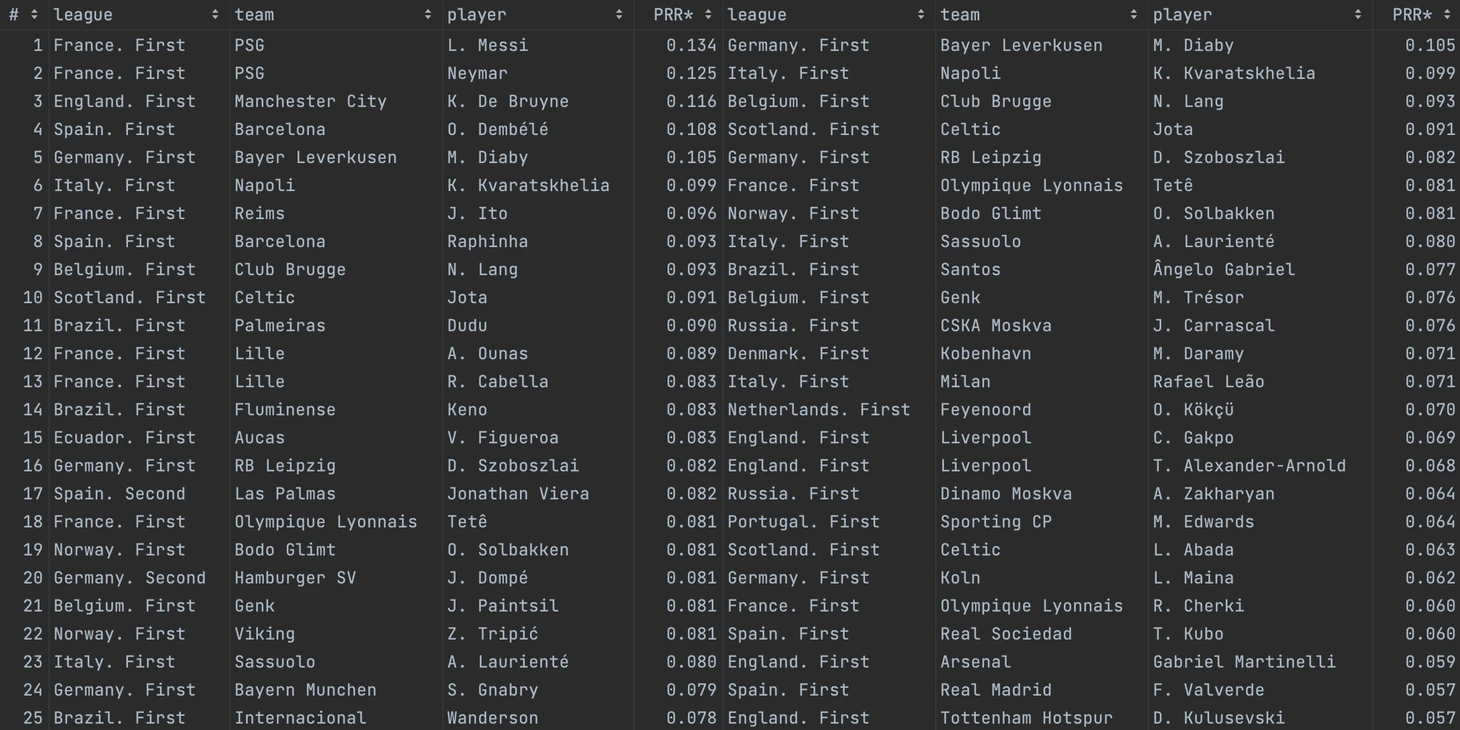
Шорт-листы для Бока Хуниорс:
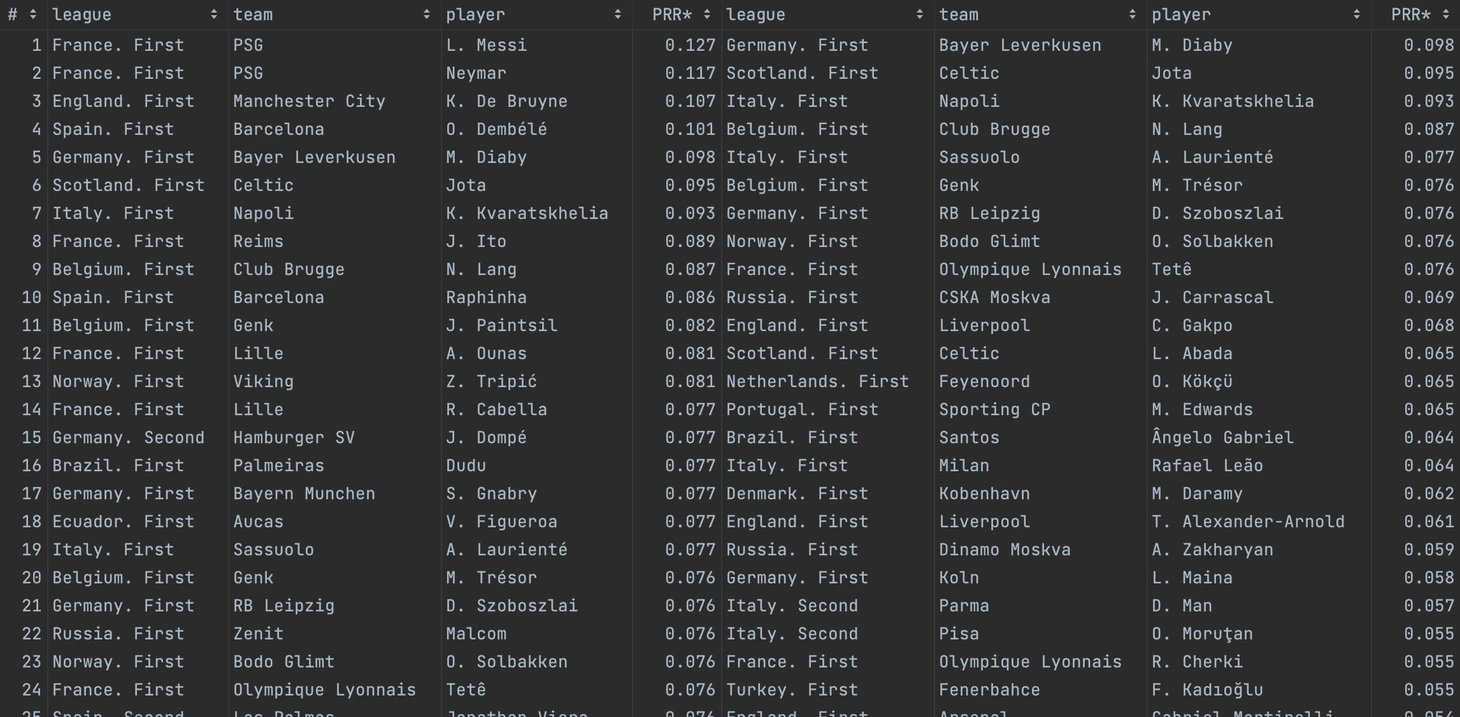
Парочка замечаний
Не то, чтобы режет глаз, но заметно, что модель рекомендует футболистов из своего чемпионата немного охотнее. Возможно, модель понимает, что у таких игроков адаптация будет проходить проще.
Обычно свои статьи я завершаю частью, где описываю проблемы моего подхода. Но они были изложены в предыдущих частях. В приведенных списках есть странные футболисты, которых вряд ли кто-то захочет приобрести. Однако замечу, что изначально не ставилась задача создать идеальный рейтинг футболиста. Скорее хотелось придумать способ фильтровать совсем плохих игроков.
















Комментарии