На Sports.ru своя модель xG. Как она работает?
Объяснение, которое поможет правильнее воспринимать данные.
Перед стартом чемпионатов мы анонсировали обновление приложения, в котором добавили xG в матч-центр. На прошлой неделе в нескольких телеграм-каналах заметили, что наши данные по xG в матче «Фиорентина» – «Милан» отличаются от других поставщиков. Особенно ярок был Игорь Порошин.
«Так называемое xG нужно упразднять, как упразднил 19 век парики. Чем дальше, тем эта мода выглядит смехотворнее. «Футбол в цифрах» обсчитал вчерашний праздник «Фиорентины» в 1,11. Understat – в 1,98. А то, что публикует Sports.ru – в 3+. Это не статистика, а нумерологические авторские колонки. Пускай религиозное преклонение человека перед цифрами находит себя в чем-то другом. Мы же теперь на эту белиберду ни в каком виде ссылаться не будем».

По мнению Порошина, такая разбежка ставит под сомнение точность модели. Что ж, кажется, пора рассказать, как этот показатель вычисляется на Sports.ru и почему не у всех он одинаковый.
Четыре абзаца про математику, потому что важно проговорить систему подсчета. Если не поймете сразу, не страшно, переходите к следующей главе
Напомним, что xG – это вероятность гола при ударе. Показатель вычисляется на основе исторических данных. Грубо говоря, мы оцениваем, как часто забивали голы при определенном типе удара (о параметрах чуть ниже).
Рассчитывая xG, мы решаем довольно простую задачу из математической статистики – предсказываем будет гол или нет. Получается, что модель xG – задача бинарной классификации, где у нас есть зависимая переменная «гол» и набор независимых переменных, которые могут на нее повлиять. Представим, что независимых переменных всего две, тогда их довольно просто показать на графике:
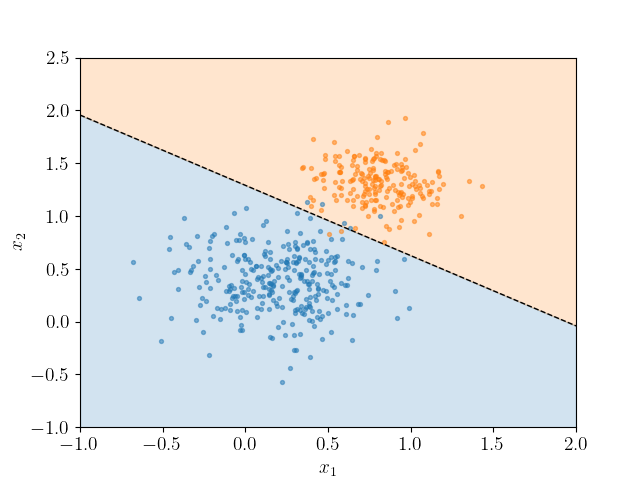
Вспомним школьное уравнение прямой x2 = ax1+b (где a – коэффициент угла наклона, а b – коэффициент сдвига по оси x2), и тогда задача сводится к тому, что нужно подобрать такие значения коэффициентов, чтобы разделить плоскость при помощи этой прямой таким образом, чтобы максимальное число точек было в зоне того же цвета. Наша модель отличается от примера на графике только тем, что пространство независимых переменных – многомерное, и наглядно изобразить его не получится.
В математические нюансы расчета и оптимизации обучения типа градиентного бустинга над деревьями решений углубляться не будем, но там тоже есть интересные моменты: например, разбалансировка классов. Это значит, что в нашем случае нужно учитывать, что голов на порядок меньше, чем остальных ударов.
Важно отметить, что идеальных моделей классификации не существует: чем сложнее контекст решаемой проблемы, тем больше факторов может влиять на ее результат. Очень хорошо это заметно на примере из графика: часть точек синего цвета лежит на области оранжевого, и наоборот – в математической статистике это называется ошибками первого (False Positive) и второго рода (False Negative). Если перенести контекст на футбол, в первом случае – это недавний гол Бираги с центра поля (xG 0,04), во втором – промах по пустым воротам с метра.
По каким данным высчитывается xG?
Большинство спортивных медиа используют сырые данные StatsPerform или StatsBomb, где каждое событие матча – отдельная строка, всего за игру таким образом собирается порядка двух тысяч ивентов, среди которых есть все действия с мячом: удары, пасы, борьба, отборы и так далее. В нашем случае есть данные по топ-5 лигам + РПЛ с сезона-18/19, соответственно, и модель можем обучить только на них. То есть база исторических данных – более 5 сезонов в 6 чемпионатах.
Что мы используем для расчета xG? Для базовой модели достаточно только координат удара, но, очевидно, точность у нее будет маленькой. Ведь то, что событие происходит в одной точке, не значит, что игровые ситуации одинаковые. Например, Understat на основе исторических данных по ударам из центра штрафной оценил момент, когда Габриэль Мартинелли бил в пустые ворота «Астон Виллы» в xG 0,63. И это довольно низкая точность прогноза. Как решить эту проблему?

Мы стараемся добавить как можно больше известных данных, чтобы увеличить качество модели, но при этом избежать переобучения или аномального влияния некоторых переменных. Например, мы сознательно отказались от маркеров big chance (явный момент) и one-on-one (выход один на один), потому что вероятность гола при них настолько высока относительно других ударов, что влияние остальных переменных оставалось незамеченным. Если оставить эти факторы, модели достаточно смотреть только на два этих поля: если один из них равен единице, значит «был» гол, остальные параметры будут игнорироваться, соответственно, и xG будет в большинстве случаев будет близок либо к единице, либо к нулю – нас это не устраивает.
В статье Вадима Лукомского об xG отдельно упоминается один из недостатков базовой модели – она ничего не знает о бьющем игроке, считая всех одинаковыми. Но мы обогащаем события физическими характеристиками (рост/вес), позицией и рабочей ногой игрока. Это может добавить качества при кроссах (например, высокий нападающий лучше ударит головой, чем маленький центральный полузащитник) или выходах один-на-один.
Мы учитываем не только событие удара, но и два предыдущих действия, чтобы лучше понимать контекст. Эти дополнительные данные позволяют узнать скорость атаки, характер передачи или заметить, например, перехват нападающим мяча при пасе между центральными защитниками.
В итоге для каждого удара у нас есть 76 независимых переменных и одна зависимая.
Среди общих: тип действия (пас / удар / и так далее), часть тела (левая нога, правая нога / голова / остальное), координаты (отдельно x и y), расстояние до ворот, угол до центра ворот, тайм, время с начала матча и тайма, разница во времени с предыдущим событием, позиция, рост, вес и рабочая нога (или обе) игрока, количество забитых голов каждой из команд и разница в счете, хозяева или гости атакуют.
Для удара: несколько типов зон, например caley zone matrix, где финальная треть разбивается на 7 разных областей таким образом, что чем ближе к штрафной, тем зона меньше.
Для предыдущих событий: движение мяча по координатам (x, y и общий вектор), маркер удачного действия, скорость движения мяча, конечные координаты события.
Иными словами, все эти параметры помогают нам точнее нарисовать цифровой портрет удара.
Первая обученная нами модель имела метрику эффективности классификации (их много, мы используем log loss) около 99,95%, финальная – около 90%. Почему так? Зачем вообще разделять разделять переменные для ударов и предшествующих моментов? Чем больше метрика, тем лучше работает классификатор, но эти параметры добавляют нам знания, которых в момент удара быть не должно. Конечные координаты и остальные их производные позволяют понять, был удар в створ или нет, из-за чего модель переобучается и отдает этим параметрам большую значимость, и возникает та же ситуация, что с big chance и one-on-one.
В результате мы построили модель, которая может предсказывать вероятность гола (тот самый xG) по набору параметров. Возможно, в первой версии учли не все, если есть идеи, как ее улучшить – пишите в комментариях.
Так зачем вообще нужен xG, если с ним столько сложностей?

Очевидно, что xG не дает всей картины, лишь помогает бегло оценить атаку/оборону команды или остроту футболиста в отдельном матче или на дистанции, а также понять, насколько случаен результат. Ровно как необычные обороты речи и едва уловимые отсылки удерживают нас в книгах и подкастах, расширенная статистика помогает понимать футбол тем, кто хочет замечать чуть больше обычного. Если их исключить, вряд ли пострадает смысл сказанного или изменится счет в матче, но моментов, когда захочется узнать что-то новое, станет существенно меньше.
В Sports.ru мы работаем и над другими моделями, которые пока доступны только для внутреннего тестирования. Следите за обновлениями – и обязательно увидите другие интерпретации статистики не только в наших текстах, но и внутри продукта.
Фото: REUTERS/Ian Walton, John Sibley, Jennifer Lorenzini